Abstract
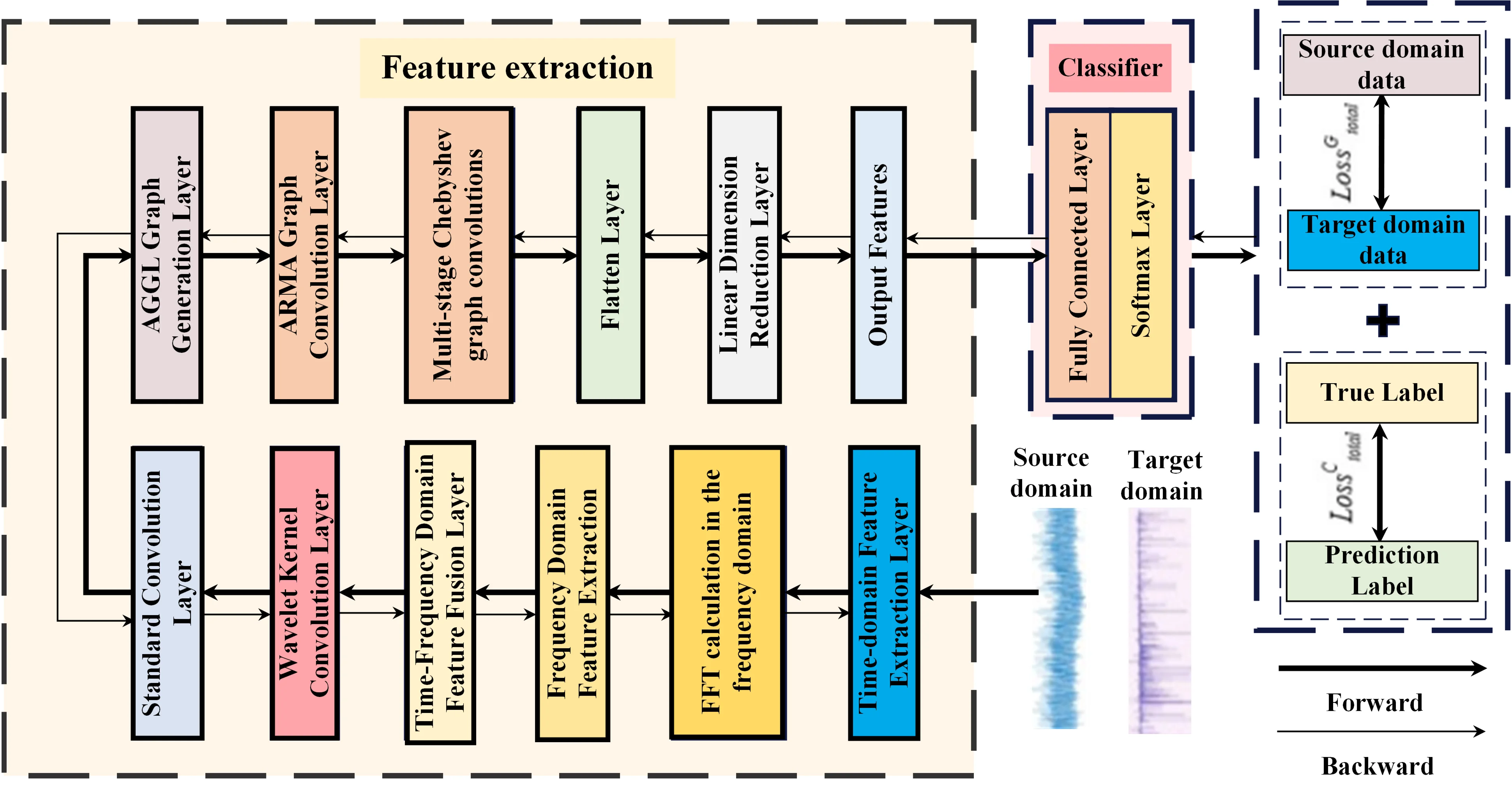
As a critical component of the automotive powertrain system, the performance status of electric motors directly impacts vehicle operational safety. During vehicle operation, sensor signals are frequently subject to noise interference, while motors typically operate under varying conditions, posing significant challenges for fault diagnosis. To address these issues, this paper proposes a cross-domain fault diagnosis method based on attention-guided graph convolutional networks, effectively countering interference from variable operating conditions. First, to tackle noise in extracted signal data, time-frequency domain feature fusion is employed to capture signal characteristics from both temporal and spectral perspectives, comprehensively extracting useful information. Subsequently, a wavelet kernel convolution layer is introduced, leveraging the multi-resolution properties of wavelet transforms to enhance feature extraction capabilities. Second, a graph-generation structure based on attention mechanisms is employed. This structure combines autoregressive moving average filter graph convolutions with multi-order graph convolutions based on Chebyshev polynomials to achieve further feature extraction and capture multi-scale information. Finally, the advancement of this method has been verified through a series of experimental cases, which demonstrates superior performance compared to other models across various cross-domain tasks.
Highlights
- A cross-domain motor fault diagnosis framework based on attention-guided graph convolutional networks is proposed for variable operating conditions.
- Time-frequency feature fusion and wavelet-kernel convolution are integrated to enhance fault representation from noisy motor signals.
- Attention-based graph generation, ARMA graph convolution, and multi-order Chebyshev convolution are combined to capture multi-scale relational features.
1. Introduction
Electric vehicles, as the core carriers of modern road transportation, play a vital role in national economic development, logistics systems, and low-carbon policies. With the continuous increase in vehicle ownership and mileage, higher demands are placed on driving safety, stability, and operational efficiency. As the core component of an electric vehicle’s powertrain, the health status of the motor directly determines driving safety, power output stability, and range capability. However, unlike controlled laboratory settings, in-vehicle motors are routinely exposed to sustained high-load operation, complex road-induced vibrations, and frequent start-stop transients, leading to strongly time-varying operating conditions and non-stationary, interference-prone monitoring signals. Under such variable operating conditions, the probability of failures occurring in internal components such as windings, bearings, and rotors significantly increases [1]. More importantly, these coupled variations in operating regimes and signal quality widen the practical gap for fault diagnosis: diagnostic models must remain accurate and reliable when conditions drift in real driving scenarios. Therefore, conducting precise fault diagnosis (FD) research on automotive motors under variable operating conditions is crucial for ensuring the safe and reliable operation of vehicles, preventing driving interruptions or even safety incidents caused by motor failures.
Data-driven intelligent methods have created new opportunities for FD, as they can automatically learn complex feature representations from large-scale data without relying on handcrafted feature design, thereby showing clear advantages in FD tasks [2-3]. For example, Zhang et al. [4] developed an integrated sparse supervision model based on sparse feature extraction, enabling efficient FD. Liu et al. [5] proposed a multi-domain CNN that achieves high-precision motor bearing diagnosis by jointly extracting one-dimensional and two-dimensional features. He et al. [6] constructed an FD approach for train traction motor bearings using multi-sensor data fusion, where deep and shallow features across different spatial dimensions are captured via a fused three-dimensional pixel matrix. Nevertheless, automotive motors typically operate under complex and highly variable conditions. The above methods often require time-consuming and labor-intensive data collection for each specific operating condition to train or calibrate models, which limits their practicality when operating conditions change frequently. Moreover, variations in operating regimes can induce pronounced, dynamic shifts in signal characteristics, making fault-related features harder to extract consistently and reliably. Consequently, FD models are confronted with stringent requirements in terms of generalization and adaptability under changing conditions.
Cross-domain diagnostics have become a current research hotspot due to their ability to infer and reflect the characteristic manifestations of identical faults under other operating conditions by leveraging common fault features extracted from partial operating condition data. For example, Kim et al. [7] proposed a preprocessing method for stator current operational compensation. By resampling and recalibration, each learning sample was made to contain the same electrical angle period, and amplitude differences were equalized. This significantly mitigated distribution drift caused by operating condition variations such as speed and torque, thereby improving the robustness and accuracy of PMSM FD under multiple operating conditions. Li et al. [8] proposed a knowledge mapping-based adversarial domain adaptation method. Within an adversarial learning framework, it combines discriminative feature distance metrics with auxiliary classifiers. By utilizing a knowledge mapping module to extract domain-invariant features, the approach significantly reduces the distributional differences between the source and target domains under varying operating conditions. Zhu et al. [9] proposed a FD method for variable operating conditions. It first converts vibration signals into vibration images to fully characterize time-frequency and texture information, then constructs a domain-adaptive network to perform alignment at both global and subdomain levels. This approach achieves high-accuracy, strong-generalization intelligent diagnostic performance across multiple operating conditions. However, during vehicle operation, the motor faces multi-source coupled excitation, causing the acquired signals to suffer from noise interference. The aforementioned methods struggle to effectively address diagnostic tasks under varying noise conditions. Furthermore, the accurate extraction of cross-domain features remains a significant challenge. Conventional FE methods struggle to adapt effectively to the dynamic operating conditions encountered during vehicle operation, resulting in low diagnostic accuracy.
CNNs have found extensive application in the field of FD due to their exceptional FE capabilities. Through the synergistic interaction of convolutional and pooling layers, CNNs can extract local features from fault data and progressively construct higher-level feature representations [10-12]. However, although CNNs are able to progressively build more global representations by stacking multiple convolutional layers, their feature extraction is still largely achieved by aggregating local receptive-field patterns. As a result, it can be difficult for CNN-based models to explicitly capture long-range dependencies and complex correlations embedded in the global information. In contrast, graph convolutional networks can naturally represent the underlying structure of samples as association graphs, where nodes and edges encode entities and their interactions. This graph-based formulation enables the model to directly model intricate relationships among sample data, and to more thoroughly explore the spatial dependencies and temporal dynamics within the data, leading to richer and more informative representations for downstream analysis. Therefore, GCNs can compensate for the shortcomings of CNNs and significantly enhance fault classification capabilities [13]. The core idea of GCNs is to update node feature representations by aggregating information from nodes and their neighbors, thereby capturing both global and local information within the graph structure to achieve outstanding performance [14-15]. In recent years, researchers have begun applying GCNs to the field of FD, achieving significant progress. Li et al. [16] proposed a multi-receptive field GCN that aggregates information from different neighborhoods using multi-receptive field graph convolutional layers. This approach achieved high-accuracy FD across multiple complex mechanical fault datasets and demonstrated excellent robustness under conditions of extreme sample imbalance. Cao et al. [17] introduced a novel pulse graph attention network for intelligent FD of planetary gearboxes, enabling simultaneous extraction of spatio-temporal features from gearbox signals. Yu et al. [18] proposed a two-stage importance-aware subgraph CNN based on multi-source sensors, enhancing the fault recognition performance of intelligent neural networks under variable conditions and limited data. Ma et al. [19] introduced a self-attention GCN employing fast local spectral filters based on Legendre polynomials and self-attention graph pooling methods, significantly improving model stability and computational efficiency. Han et al. [14] proposed a complex industrial process FD method based on multi-relational fusion GCN and multi-scale residual networks, effectively handling multi-scale temporal correlation features and comprehensively representing complex relationships among sensors. Evidently, graph neural networks hold immense promise for fault diagnosis in complex systems. By explicitly modeling the structured relationships among multiple sensing channels and components, they can more comprehensively uncover latent fault characteristics both across signals and within individual signals. This capability enables the construction of more accurate, discriminative, and interpretable feature representations, thereby providing a solid foundation for reliable and precise subsequent diagnostic decision-making.
Although the existing data-driven and cross-domain fault diagnosis methods have achieved satisfactory results, they still face several significant challenges in real automotive motor diagnosis, including insufficient adaptability to rapidly changing operating conditions, limited robustness under noise interference, and insufficient ability to extract global structural features from complex monitoring signals. These limitations hinder reliable fault diagnosis in actual driving scenarios. To address these issues, this study explores cross-domain fault diagnosis of automotive motors under changing operating conditions and proposes an attention-guided graph convolutional network (AGGCN) to achieve more robust feature representation and more accurate fault classification. The main contributions of this study are summarized as follows:
(1) A method combining time-frequency domain feature fusion with wavelet kernel convolution is proposed to achieve deep extraction of signal features in noisy environments.
(2) To address the challenge of FE in cross-domain diagnostics under variable OC, a fusion approach is proposed. It integrates a graph generation structure based on attention mechanisms, autoregressive moving average filter graph convolutions, and a multi-order GCN based on Chebyshev polynomials. This enhances FE capabilities and effectively captures multi-scale information.
(3) Integrating the aforementioned approaches forms a graph convolutional-based cross-domain FD method, whose reliability is validated using the GXU motor fault dataset.
2. Background information
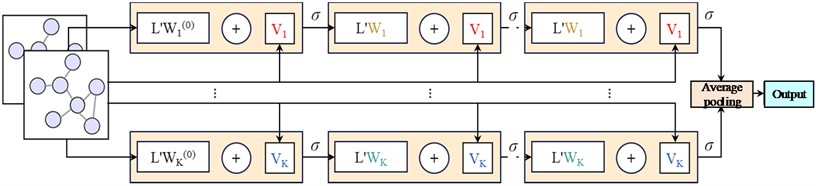
2.1. ARMA graph convolution
Auto-regressive moving average (ARMA) graph convolution [20] is implemented based on auto-regressive moving average filters. Compared to polynomial graph convolutions, such as Chebyshev graph convolutions, ARMA graph convolutions offer more flexible frequency responses, capture better graph-global structures with fewer parameters, and exhibit superior noise resistance against noise in graph signals. The operation of ARMA filters is illustrated as follows:
Its frequency response formula is:
where, denotes the order of the filter, represents the eigenvalues of the Laplace matrix, and are the filter coefficients that are automatically updated through training, and is the identity matrix used to preserve the dimensions and structure of the matrix.
In the node space, the filtering relationship of the ARMA filter is:
where, is the symmetric normalized Laplacian matrix (LM) of the graph, is the graph signal, and is the filtered graph signal.
ARMA filters are implemented through recursive approximation. For a first-order ARMA filter, the recursive update formula is:
where, and represent the maximum and minimum eigenvalues of the Laplace matrix, and denote learnable parameters, and indicates the number of recursive iterations.
Then, based on the convergence of Eqs. (4-6), the frequency response of a first-order ARMA filter can be defined as:
Among them, the eigenvectors of and Lare identical, but their eigenvalues differ. If is an eigenvalue of and is an eigenvalue of , then the relationship is as follows:
Let , when , the first term is:
The second item is expressed as:
Therefore, the frequency response of a first-order ARMA filter is:
By summing K first-order ARMA filters, the analytical form of the ARMAK filter can be recovered. The filtering operation is:
where, denotes the th eigenvector of the graph’s LM .
By setting coefficient to zero, the ARMA filter is converted into a polynomial filter.
Furthermore, by the recursive formula, the ARMA graph convolution is defined as:
where, is the activation function, is the initial node feature, and are trainable parameters, and is the modified LM, which is appropriately simplified by setting and .
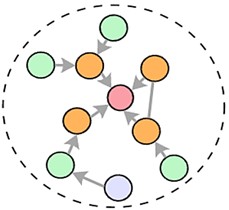
The ARMA graph convolutional architecture is shown in Fig. 1, where identical colors indicate weight sharing.
Fig. 1Workflow diagram of the ARMA graph convolution architecture
2.2. Chebyshev graph convolutions
This model employs Chebyshev graph convolutions of varying orders [16] to capture multi-scale features within the graph. The feature update process for multi-order Chebyshev graph convolutional nodes is illustrated in Fig. 2. The parameter specifies the degree of the Chebyshev polynomial used in the convolution process. When , the convolution kernel primarily focuses on a node’s first-order neighbors. When 2, the kernel considers both first- and second-order neighbors, and so on.
Chebyshev graph convolutions approximate spectral graph convolutions using Chebyshev polynomials. The principle is illustrated by Eqs. (13-15).
Graph convolution is based on the eigenvalue decomposition of the graph LM . The definition of the LM is shown in Section 2.2.1. Graph convolution is expressed as:
where, is the matrix of eigenvectors of , is the matrix of eigenvalues, is the filter of the graph network, which is a function of the eigenvalues of with respect to the parameter , and is the vector of Fourier coefficients.
To improve computational efficiency, Chebyshev polynomial is used to approximate :
where, denotes the degree of the Chebyshev polynomial, and represents the learnable parameter.
The output of a Chebyshev GCN can be expressed as:
Fig. 2The convolution principle of Chebyshev polynomials of different orders
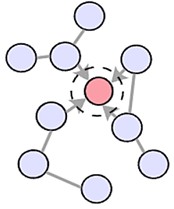
a)
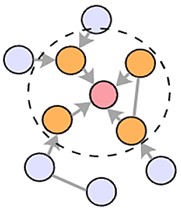
b)
c)
3. Methodology
3.1. Data processing methods
Perform preliminary time-domain and frequency-domain FE and fusion on the input signal. Time-domain FE processes the input signal through convolution layers, batch normalization layers, activation layers, and max pooling layers to extract local temporal features within the signal. Convolution operations capture local patterns within the signal, while the max pooling layer reduces the spatial dimension of features while preserving important information. Frequency domain FE transforms the input signal from the time domain to the frequency domain using the fast fourier transform (FFT). Frequency domain features are then extracted through a sequence of convolution layers, batch normalization layers, activation layers, and max pooling layers.
Subsequently, the multi-resolution analysis property of the wavelet transform is utilized to initialize the convolution kernel. By performing a sliding pointwise multiplication between the wavelet kernel and the input signal, features related to the shape and frequency characteristics of the wavelet kernel are extracted. When a local region of the input signal matches the shape and frequency characteristics of the wavelet kernel, the convolution operation produces significant response values. These response values form a feature map reflecting wavelet-related characteristics within the input signal, thereby simultaneously capturing both high-frequency details and low-frequency trends.
The Daubechies 4 (db4) wavelet is a commonly used compactly supported orthogonal discrete wavelet with excellent time-frequency localization properties. Its scale function and wavelet function represent the low-frequency and high-frequency components of a signal, respectively, serving to smooth the signal and capture its rapid variations in the wavelet transform. In this study, the wavelet kernel convolution layer utilizes db4 wavelet filter coefficients to initialize the convolution kernel, with a precision level of 5 during wavelet function generation. Owing to its superior multiscale analysis capabilities and frequency selectivity, the db4 wavelet effectively extracts both local features and global trends within signals, providing a rich information foundation for subsequent feature processing and model training.
3.2. Graph convolution neural network
This section proposes an attention-based graph generation method-the attention-mechanism graph generation layer (AGGL)-which enhances the modeling capability of graph neural networks for complex data relationships by dynamically constructing graph structures. AGGL incorporates the squeeze-and-excitation (SE) attention mechanism [21]. By learning importance weights across feature channels, the SE attention mechanism recalibrates features and calculates attention scores between nodes based on these calibrated features. Simultaneously, the introduction of self-loops and threshold control further enhances the robustness and flexibility of the graph structure. Subsequently, the features of each signal sample are treated as graph nodes, and attention scores and weights are dynamically computed based on feature relationships between nodes to generate the graph structure. Fig. 3 shows its specific structure.
Fig. 3Attention-based graph generation architecture
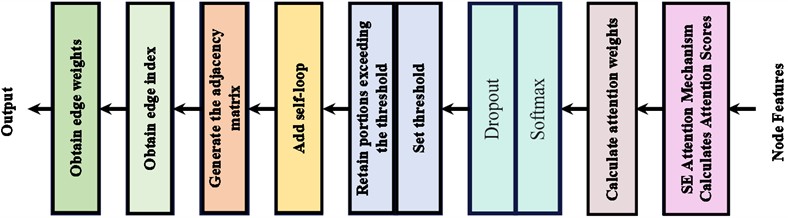
The SE attention mechanism first performs a Squeeze operation on the input features, compressing the channel dimension through global average pooling to extract global information. It then executes an Excitation operation, utilizing two fully connected (FC) layers and two nonlinear activation functions (ReLU and Sigmoid) to learn the importance weights for each channel, generating a weight vector. Finally, the learned weights are element-wise multiplied with the original features, amplifying important features while suppressing unimportant ones, yielding calibrated features.
The graph generation process based on the attention mechanism is as follows:
Attention scores are computed directly by the SE attention mechanism layer, where attention weights reflect the relationships between nodes. A random dropout layer reduces complex mutual adaptation among neurons, preventing overfitting:
Among these, is the attention score matrix, is its transpose matrix, represents the attention weights between nodes, and denotes the SE attention mechanism layer.
To reduce computational load while preserving critical information, an intensity threshold was set for sparsification. Self-loops were added to enhance nodes’ self-feature representations, thereby generating an adjacency matrix containing global information:
Among these, represents the adjacency matrix considering self-loops, denotes the threshold operation, in order to reduce the computational load while retaining the key structural information, a threshold operation will be performed on the adjacency matrix to achieve sparsification. The range of this value is usually 0.6-0.8. Following the values used in previous studies, in this research, the threshold has been empirically set to 0.7 [22, 23], and is the identity matrix containing the node's intrinsic features.
Finally, the edge weights and indices are extracted for subsequent operations. An ARMA layer is constructed based on ARMA filters to capture multi-scale features of nodes in the graph. This ARMA layer consists of two parallel branches, each containing three layers of ARMA filters (iterated three times), progressively extracting deeper-level features. Each branch learns two distinct filter responses, thereby capturing two sets of features at different scales. Subsequently, a residual connection sums the original features with the extracted features, enabling the model to converge more rapidly to a higher level of accuracy.
The Chebyshev graph convolutional layer is configured with set to 1, 2, and 3 to capture features at different scales [24, 25]. The detailed process of the complete multi-scale fusion graph convolutional layer is shown in Eqs. (19-25):
Among these, represents the input sample signal, indicates the features processed through the multiscale fusion graph convolution layer, while and correspond to the edge connectivity information and weights of the adjacency graph obtained after passing through the graph generation layer AGGL.
Using cross-entropy loss to feed back classification loss, the classification loss function is expressed as follows:
where, represents the total sample size, denotes the input of the th sample in category , is the feature extractor, and is the classifier composed of a FC layer and a Softmax layer. indicates that if sample is estimated as belonging to class , then ; otherwise, is 0.
Use adversarial networks to construct the loss function [26]. By minimizing the distributional difference between the source and target domains, the feature extractor generates domain-invariant features. Specifically, adversarial training is applied to the domain discriminator to distinguish whether data originates from the source or target domain. A binary cross-entropy loss function is then used to compute and minimize the discrepancy against the true labels. Finally, gradient reversal ensures the feature extractor and domain discriminator compete against each other, compelling the FE to generate features common to both domains.
The adversarial loss function is expressed as follows:
where, represents the total number of samples. and denote the feature values extracted from samples in the source domain and target domain, respectively. is the domain discriminator. and indicate whether a sample is correctly predicted as belonging to the source domain or target domain; if so, they are 0, otherwise 1.
The total loss function is:
3.3. FD process
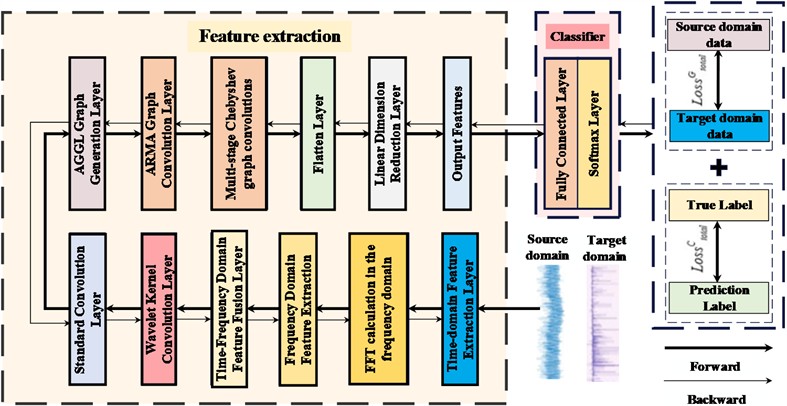
As shown in Fig. 4, this model first performs time-domain FE on the input signal, then converts the time-domain signal to the frequency domain through the FFT for FE, and then integrates it with the time-domain features. Subsequently, it undergoes deep FE using the wavelet kernel convolution layer and the ordinary convolution layer. Then, it passes through the input graph generation layer, the ARMA graph convolution layer, and the multi-order Chebyshev graph convolution layer to achieve further FE. Finally, it enters the subsequent classifier after passing through the flattening layer and the dimensionality reduction layer.
The signals collected by the sensors are labeled and randomly shuffled. The resulting samples are divided into training, validation, and test sets according to specific proportions. The AGGCN model parameters are trained and optimized using the training and validation samples. Finally, the trained model is employed as a pattern recognition algorithm for motor FD, with its overall diagnostic performance validated and analyzed through the test set.
Fig. 4The schematic diagram of the AGGCN fault diagnosis process proposed in this article
4. Experiments and results analysis
Because it is difficult for the motor to operate with faults for a long time in the vehicle, it makes it difficult to obtain real data. Therefore, this paper uses the data set collected from the experimental test bench to verify and compare the proposed finite element method based on graph convolution. This dataset originates from a motor fault simulation test bench manufactured by Guangxi university, designed for collecting simulated data on various motor faults. It is named the GXU Motor Fault Dataset. All experiments in this section and subsequent sections are implemented using the PyTorch framework and PyCharm software. The primary configuration of the experimental computer includes a GeForce RTX 3090 Ti graphics card with 24GB of VRAM and the Ubuntu 20.04 operating system.
4.1. Case study 1
4.1.1. Signal acquisition
The GXU motor fault data acquisition device is shown in Fig. 5. This device comprises an GXU-F0.7 dynamometer, a hysteresis brake, and a fault motor. The hysteresis brake operates based on the principle of magnetic hysteresis, generating specific torque by adjusting the input excitation current. The motor fault types encompass the following seven categories: - Built-in bearing fault (outer ring raceway defect: width 0.5 mm × depth 0.3 mm) - Built-in imbalance fault - Built-in warping fault - Built-in static eccentricity fault - Built-in dynamic eccentricity fault - Built-in rotor bar breakage fault - Built-in bearing fault (rolling element defect: width 0.5 mm × depth 0.3 mm) The different motor fault types used in this experiment and their corresponding labels are shown in Table 1.
Fig. 5GXU motor multi-type fault data acquisition experimental platform. Photo by Zhenzhen Jin, Transportation Equipment Laboratory of the Mechanical Engineering College of Guangxi University, March 1st, 2025




In this study, the operating conditions were varied by applying different load torque levels at a constant rotational speed. Therefore, this experiment mainly evaluated the cross-domain diagnostic performance of the proposed method under load variation conditions. Based on the torque corresponding to 0 %, 10 %, and 20 % of the rated excitation current (500 mA) at a rotational speed of 20 Hz, these conditions are defined as OC1, OC2, and OC3, respectively. The specific settings for different cross-domain diagnostic tasks are shown in Table 2. This model employs an end-to-end approach, directly feeding signal data from the dataset into the network for FE and classification. The signal data consists of one minute of sampled data after the motor stabilizes, with a sampling frequency of 20 kHz and a sample length truncated to 3072. After sliding window extraction, each fault type yields 325 samples. A total of seven faults were tested, resulting in 2275 samples per task. In the source domain data, 80 % is allocated for training and 20 % for validation. In the target domain data, 20 % is reserved for testing.
Table 1Seven types of motor failures and their corresponding labels
Label | Fault type | Fault explanation |
0 | Fault of the outer ring raceway | Damage has occurred to the raceway of the outer ring inside the bearing |
1 | Unbalanced fault | Uneven rotor mass distribution |
2 | Warpage fault | The rotor or shaft has become bent or deformed |
3 | Static eccentricity fault | The center of mass of the rotor is not on the axis of rotation |
4 | Eccentricity fault | The center of mass of the rotor shifts during rotation |
5 | Rotor bar breakage failure | A metal strip inside the rotor has fractured, resulting in uneven mass distribution |
6 | Bearing rolling element fault | The rolling elements inside the bearing have been damaged |
Table 2Cross-domain diagnostic task
Task number | Source domain | Target domain |
1 | OC1 | OC2 |
2 | OC1 | OC3 |
3 | OC2 | OC1 |
4 | OC2 | OC3 |
5 | OC3 | OC1 |
6 | OC3 | OC2 |
4.1.2. Cross-domain FD performance comparison analysis
To comprehensively evaluate the performance of the AGGCN model proposed in this chapter, five reference models were selected for comparison: Deep adversarial network for domain adaptation via backpropagation (DANN) [27]; Correlation-based alignment network for deep domain adaptation (CORAL) [28], Graph isomorphism network (GIN) [29], Domain-adversarial GCN under variable conditions (DAGCN) [30], Batch spectral penalty network for adversarial domain adaptation (BSP) [31]. AGGCN hyperparameters were set as follows: batch size 64, learning rate 0.001, training for 200 epochs, with gradient decay to 0.00001 starting from epoch 150. Hyperparameters for other models followed their original papers. Each method underwent five independent runs across all tasks to eliminate random variations and ensure result accuracy and reliability.
Table 3Comparison table of model FD accuracy under different operating conditions
Model Task | AGGCN | DANN | CORAL | GIN | DAGCN | BSP |
1 | 96.39 % | 94.20 % | 83.84 % | 86.84 % | 62.72 % | 51.56 % |
2 | 93.71 % | 90.48 % | 77.53 % | 70.03 % | 64.91 % | 53.75 % |
3 | 98.25 % | 94.05 % | 80.21 % | 91.08 % | 61.11 % | 65.50 % |
4 | 93.12 % | 89.73 % | 90.03 % | 75.73 % | 69.01 % | 64.06 % |
5 | 97.22 % | 90.48 % | 78.72 % | 81.55 % | 54.66 % | 29.38 % |
6 | 96.49 % | 92.26 % | 91.82 % | 78.95 % | 58.77 % | 27.81 % |
Mean | 95.86 % | 91.87 % | 83.69 % | 80.70 % | 61.86 % | 48.68 % |
As reported in Table 3, the proposed AGGCN achieves the best FD performance across all six cross-condition tasks, yielding a mean accuracy of 95.86 %. This result consistently surpasses the competing domain adaptation and graph-based baselines, including DANN (91.87 %), CORAL (83.69 %), GIN (80.70 %), DAGCN (61.86 %), and BSP (48.68 %), corresponding to improvements of 3.99, 12.17, 15.16, 34.00, and 47.18 percentage points, respectively. Notably, AGGCN maintains a high and stable accuracy range (93.12 %-98.25 %) under different transfer settings, indicating strong robustness to operating-condition variations. The comparative advantage suggests that merely aligning global feature distributions (e.g., DANN/CORAL) or relying on less adaptive relational modeling (e.g., GIN/DAGCN/BSP) may be insufficient when signal characteristics shift with speed/load changes. From a practical perspective, such consistent cross-condition performance implies that AGGCN can reduce the dependence on collecting and labeling large amounts of data for every single operating condition, thereby improving the feasibility of deploying FD models for automotive motors in real driving scenarios where operating regimes change frequently.
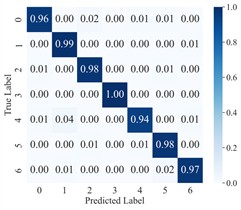
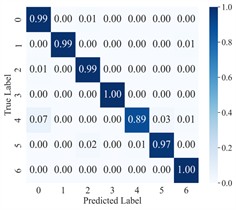
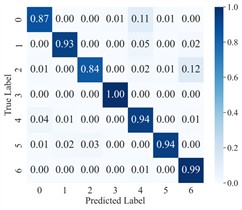
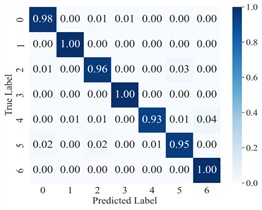
To more clearly demonstrate the model’s classification performance across different fault categories and to verify the effectiveness of feature extraction (FE), the diagnostic results of AGGCN are illustrated using a confusion matrix (Fig. 6) and t-SNE visualization (Fig. 7). As shown in these figures, Task 2 and Task 4 exhibit comparatively lower classification accuracy when operating conditions 1 and 2 are used for training and condition 3 is used for testing, whereas Task 5 and Task 6 achieve higher accuracy after swapping the training and testing sets. This performance asymmetry suggests that the discriminative characteristics among fault classes are less salient under lower-load regimes than under higher-load regimes. From a representation-learning perspective, lower loads typically lead to weaker fault excitations and reduced energy in fault-related components, which may compress inter-class feature distances and increase feature overlap, thereby making the decision boundaries less separable. In contrast, higher loads tend to intensify fault-induced responses and amplify subtle fault signatures, enabling the model to extract more distinctive and stable features and thus improving cross-condition generalization.
Fig. 6Confusion matrix of AGGCN under different task conditions
a) Task 1
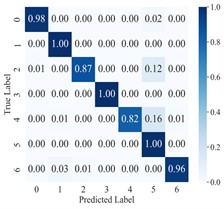
b) Task 2
c) Task 3
d) Task 4
e) Task 5
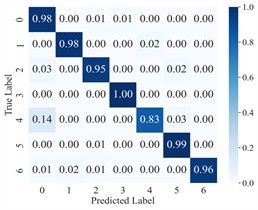
f) Task 6
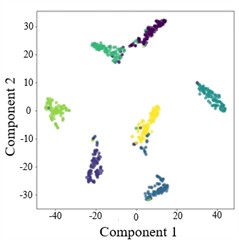
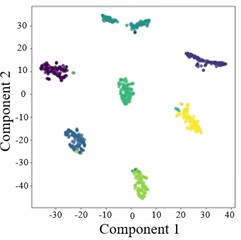
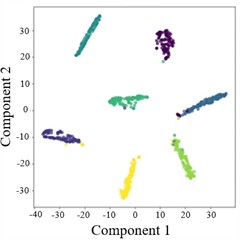
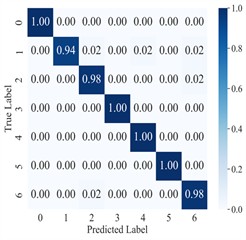
Moreover, the visualization results indicate that, regardless of the task setting, fault 3 consistently achieves 100 % classification accuracy, implying that its intrinsic signature is highly distinctive and forms a well-separated cluster in the learned feature space. By comparison, fault 4 presents a lower classification accuracy, which likely reflects a higher degree of similarity with other fault types and stronger susceptibility to operating-condition shifts and noise interference, causing partial cluster mixing in the embedding space and leading to misclassifications. This observation further highlights the importance of capturing fine-grained relational patterns and condition-invariant characteristics for confusing fault pairs, and it motivates deeper analysis of the extracted features (e.g., inter-class separability, intra-class compactness, and boundary samples). Overall, across a range of variable operating conditions, the proposed model maintains robust predictive performance and exhibits strong practical potential for real-world deployment.
Fig. 7T-SNE plots of AGGCN under different operating conditions and tasks
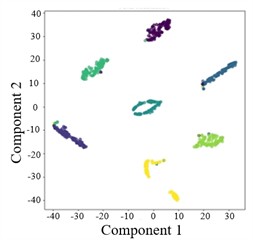
a) Task 1
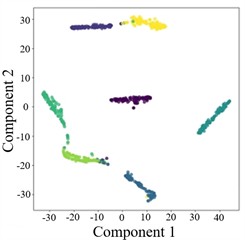
b) Task 2
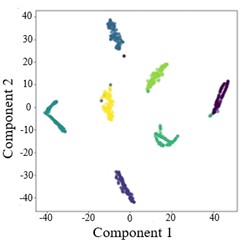
c) Task 3
d) Task 4
e) Task 5
f) Task 6
4.1.3. Comparative analysis of cross-domain FD performance under noise conditions
The fault samples used in this experiment inherently contain a significant amount of noise. To fully extract shared features among samples within the same fault category, the experiments were conducted using operating conditions 1 and 2 as the training set and operating condition 3 as the test set. All other settings remained consistent with Section 4.1.2.
The signal-to-noise ratio is a metric that measures the ratio of the power of the useful signal to the power of the noise in a signal, typically expressed in decibels (dB). A higher signal-to-noise ratio indicates better signal quality relative to noise, meaning the signal is clearer. The formula for calculating the signal-to-noise ratio is shown in Eq. (29):
In the comparative analysis, the proposed AGGCN model employs a batch size of 64 and a learning rate of 0.001, with gradient decay to 0.00001 starting from the 150th epoch. Other models are configured according to the hyperparameters specified in the original paper. The training cycle spans 200 epochs. Each method underwent five tests across all tasks to mitigate random factors and ensure the accuracy and reliability of the results.
Table 4 further evaluates model robustness under increasingly severe noise. AGGCN exhibits strong noise tolerance, achieving 93.06 % at 0 dB and retaining 73.25 % even at –3 dB, whereas DANN and CORAL degrade dramatically (around 25 %-30 % under noisy settings), indicating that their distribution-alignment mechanisms are highly sensitive to heavy noise contamination. Compared with the graph baseline GIN, which remains relatively robust (87.57 % at 0 dB and 68.73% at −3 dB), AGGCN still provides a consistent margin, especially at low SNR (e.g., 73.25 % vs. 68.73 % at −3 dB). DAGCN shows moderate robustness but drops substantially as noise increases (59.80 %-39.62 %). These comparative results suggest that AGGCN is better at preserving discriminative fault information under noise interference, which is critical for in-vehicle environments where measurements are often affected by road excitation, electromagnetic interference, and sensor installation constraints. Practically, this robustness reduces the reliance on aggressive denoising or strict data-collection conditions, although the performance decline at extremely low SNR also indicates that improving sensor placement, sampling strategy, and lightweight preprocessing can further enhance real-world reliability.
Table 4Comparison table of FD accuracy rates in different noise environments
Model noise | AGGCN | DANN | CORAL | GIN | DAGCN |
Noiseless | 96.39 % | 94.20 % | 83.84 % | 86.84 % | 62.72 % |
0 dB | 93.06 % | 29.84 % | 27.50 % | 87.57 % | 59.80 % |
–1 dB | 87.03 % | 29.53 % | 27.66 % | 86.70 % | 50.88 % |
–2 dB | 83.04 % | 28.44 % | 26.25 % | 79.50 % | 47.37 % |
–3 dB | 73.25 % | 27.97 % | 25.47 % | 68.73 % | 39.62 % |
The diagnostic results of AGGCN are illustrated using the confusion matrix (Fig. 8) and the dimensionality reduction visualization (Fig. 9). As can be observed, the classification accuracy of AGGCN exhibits a clear downward trend as the noise power increases, reflecting a progressive degradation of feature separability under more severe interference. Specifically, under the noise-free setting and the 0 dB condition, the model can still capture representative fault-related patterns and maintain compact intra-class clustering with relatively large inter-class margins, thereby achieving stable and accurate recognition. However, when the noise level increases to –1 dB, –2 dB, and particularly –3 dB, the number and magnitude of non-diagonal entries in the confusion matrix increase markedly, indicating that confusion among fault categories becomes more frequent. This phenomenon is also consistent with the embedding visualization, where samples from different classes gradually overlap and the cluster boundaries become less distinct, suggesting that the learned representations are increasingly dominated by noise-induced variability rather than fault-discriminative information.
Fig. 8Confusion matrix for AGGCN cross-domain diagnosis under different noise conditions
a) Noiseless
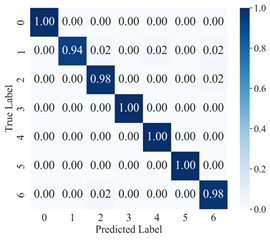
b) 0 dB
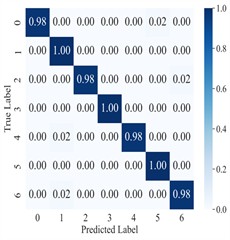
c) –1 dB
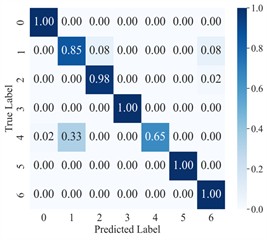
d) –2 dB
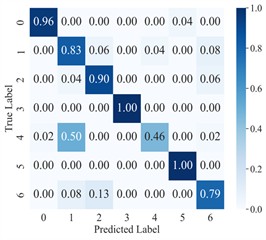
e) –3 dB
From a signal and representation learning perspective, stronger noise not only masks weak fault impulses and suppresses characteristic spectral components, but also introduces stochastic perturbations that distort temporal structures and time-frequency distributions. Consequently, the within-class variance expands while the between-class distance shrinks, which directly impairs the classifier’s ability to form robust decision boundaries. Even though AGGCN integrates time-frequency multimodal feature extraction, leverages the multiresolution and time-frequency localization properties of wavelet transforms, and benefits from the relational modeling and inherent robustness of graph convolutions, extremely strong noise can still corrupt the underlying sample correlations used to construct the graph and degrade the reliability of node/edge relationships. In other words, under high-noise regimes, both the intrinsic signal content and the cross-sample/within-sample relational cues become less trustworthy, making it increasingly challenging for the model to extract stable, condition-invariant fault features.
Nevertheless, it is noteworthy that AGGCN still achieves the best overall noise-resistance performance compared with the competing models. This advantage suggests that the proposed architecture is able to retain more informative fault cues and preserve feature structure under interference, likely due to the complementary fusion of time-frequency representations and the graph-based aggregation mechanism, which together mitigate noise sensitivity and enhance the robustness of learned diagnostic features.
Fig. 9T-SNE plots for cross-domain diagnosis of AGGCN under different noise conditions
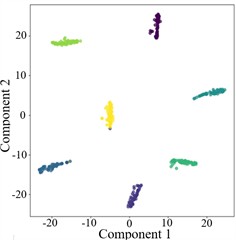
a) Noiseless
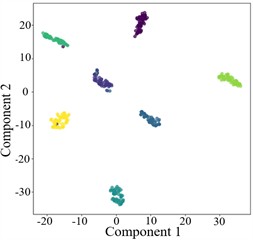
b) 0 dB
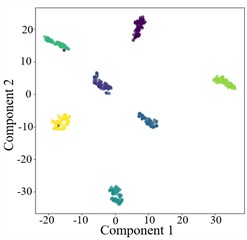
c) –1 dB
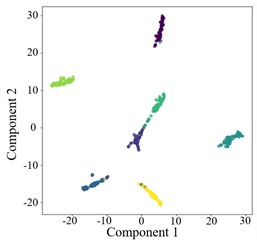
d) –2 dB
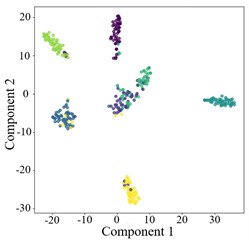
e) –3 dB
5. Conclusions
This paper proposes a graph convolutional network GCN-based motor FD method to tackle the dual challenges posed by variable operating conditions and noise interference. Extensive comparative experiments on motor datasets demonstrate the effectiveness and robustness of the proposed approach. The main contributions and conclusions are summarized as follows:
1) A signal processing strategy that integrates time–frequency domain feature fusion and wavelet-kernel convolution is developed. Specifically, time-domain information is first extracted from raw signals via convolution and max-pooling, and then transformed into the frequency domain through FFT for further feature extraction. In addition, a wavelet-kernel convolution layer is introduced after feature fusion to initialize convolution kernels with wavelet priors, thereby strengthening the model’s capability to capture localized fault-relevant patterns and improving representation quality.
2) An attention-guided GCN-based FD framework is proposed. An attention-based graph construction mechanism is first employed to recalibrate features and efficiently generate adjacency matrices, enabling more informative and task-adaptive relational modeling. A self-loop mechanism is further incorporated to explicitly account for the contribution of each node to itself. Moreover, a multi-scale feature-fusion graph convolution layer is designed to learn diverse filtering responses across multiple branches and depths, progressively mining deeper and more discriminative fault characteristics. To accelerate convergence and enhance diagnostic accuracy, residual connections are integrated. Combined with Chebyshev graph convolutions, the framework achieves effective feature fusion over neighborhoods of different scales.
3) Experimental results on the developed test platform and relevant datasets verify that the proposed method consistently outperforms representative baseline models across multiple cross-domain tasks. On the GXU motor fault dataset, the proposed model attains an average accuracy of 95.86 % in cross-domain settings. Furthermore, it maintains strong diagnostic performance under various noise levels, demonstrating the best noise resistance among the compared approaches.
Despite these promising results, there remains room for further improvement. Future work will explore more informative feature extraction strategies to better differentiate dynamic eccentricity faults from other fault types, especially under subtle excitation conditions. In addition, given the observed performance degradation as noise intensity increases, further enhancing the model’s robustness to strong noise-potentially through more noise-aware representations, adaptive graph construction, or improved denoising mechanisms-will be an important direction for continued research.
References
-
J. Ding, “Fault detection of a wheelset bearing in a high-speed train using the shock-response convolutional sparse-coding technique,” Measurement, Vol. 117, pp. 108–124, Mar. 2018, https://doi.org/10.1016/j.measurement.2017.12.010
-
Y. Xu, D. He, H. Sun, Z. Jin, and M. Zhao, “Self-supervised learning for train bearing fault diagnosis based on time-frequency dual domain prediction,” Structural Health Monitoring, p. 14759217251405584, 2026, https://doi.org/10.1177/14759217251405584
-
D. He, Y. Xu, H. Sun, Z. Jin, and M. Zhao, “Self-supervised learning for vehicle bearing fault diagnosis based on time-frequency dual-domain contrast and fusion,” Nonlinear Dynamics, Vol. 113, No. 14, pp. 17385–17412, 2025, https://doi.org/10.1007/s11071-025-11101-7
-
F. Zhang, J. Yan, P. Fu, J. Wang, and R. X. Gao, “Ensemble sparse supervised model for bearing fault diagnosis in smart manufacturing,” Robotics and Computer-Integrated Manufacturing, Vol. 65, p. 101920, Oct. 2020, https://doi.org/10.1016/j.rcim.2019.101920
-
X. Liu, W. Sun, H. Li, Z. Hussain, and A. Liu, “The method of rolling bearing fault diagnosis based on multi-domain supervised learning of convolution neural network,” Energies, Vol. 15, No. 13, p. 4614, Jun. 2022, https://doi.org/10.3390/en15134614
-
D. He, Z. Lao, Z. Jin, C. He, S. Shan, and J. Miao, “Train bearing fault diagnosis based on multi-sensor data fusion and dual-scale residual network,” Nonlinear Dynamics, Vol. 111, No. 16, pp. 14901–14924, Jun. 2023, https://doi.org/10.1007/s11071-023-08638-w
-
H. Kim et al., “Stator current operation compensation (SCOC): A novel preprocessing method for deep learning-based fault diagnosis of permanent magnet synchronous motors under variable operating conditions,” Measurement, Vol. 221, p. 113446, Nov. 2023, https://doi.org/10.1016/j.measurement.2023.113446
-
Q. Li, C. Shen, L. Chen, and Z. Zhu, “Knowledge mapping-based adversarial domain adaptation: A novel fault diagnosis method with high generalizability under variable working conditions,” Mechanical Systems and Signal Processing, Vol. 147, p. 107095, Jan. 2021, https://doi.org/10.1016/j.ymssp.2020.107095
-
M. Zhu et al., “Intelligent fault diagnosis for variable working conditions of rotor-bearing system based on vibration image and domain adaptation,” Measurement Science and Technology, Vol. 34, No. 12, p. 125105, Dec. 2023, https://doi.org/10.1088/1361-6501/aceb83
-
D. He, Y. Xu, Z. Jin, Q. Liu, M. Zhao, and Y. Chen, “A zero-shot model for diagnosing unknown composite faults in train bearings based on label feature vector generated fault features,” Applied Acoustics, Vol. 232, p. 110563, Mar. 2025, https://doi.org/10.1016/j.apacoust.2025.110563
-
Y. C. Dai et al., “Digital twin-assisted graph contrastive domain adaptation for small-sample bearing fault diagnosis,” Structural Health Monitoring, Apr. 2026, https://doi.org/10.1177/14759217261440798
-
B. Qin et al., “Robust open-circuit fault diagnosis for pmsm drives under unknown operating conditions,” IEEE Transactions on Instrumentation and Measurement, Vol. 75, pp. 1–13, Jan. 2026, https://doi.org/10.1109/tim.2026.3657549
-
G. Li, M. Muller, A. Thabet, and B. Ghanem, “DeepGCNs: Can GCNs go as deep as CNNs,” in IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9266–9275, 2019, https://doi.org/10.1109/iccv.2019.00936
-
Y. Han, S. Tuo, Y. Li, and Q. Zhao, “Multirelational fusion graph convolution network with multiscale residual network for fault diagnosis of complex industrial processes,” IEEE Transactions on Instrumentation and Measurement, Vol. 73, pp. 1–15, Jan. 2024, https://doi.org/10.1109/tim.2024.3350143
-
H. Sun et al., “CIGCN: a domain generalisation fault diagnosis method for train bearing based on causal inference graph convolutional network,” Nondestructive Testing and Evaluation, pp. 1–38, Oct. 2025, https://doi.org/10.1080/10589759.2025.2566784
-
T. Li, Z. Zhao, C. Sun, R. Yan, and X. Chen, “Multireceptive field graph convolutional networks for machine fault diagnosis,” IEEE Transactions on Industrial Electronics, Vol. 68, No. 12, pp. 12739–12749, Dec. 2021, https://doi.org/10.1109/tie.2020.3040669
-
S. Cao, H. Li, K. Zhang, C. Yang, W. Xiang, and F. Sun, “A novel spiking graph attention network for intelligent fault diagnosis of planetary gearboxes,” IEEE Sensors Journal, Vol. 23, No. 12, pp. 13140–13154, Jun. 2023, https://doi.org/10.1109/jsen.2023.3269445
-
Y. Yu, Y. He, H. R. Karimi, L. Gelman, and A. E. Cetin, “A two-stage importance-aware subgraph convolutional network based on multi-source sensors for cross-domain fault diagnosis,” Neural Networks, Vol. 179, p. 106518, Nov. 2024, https://doi.org/10.1016/j.neunet.2024.106518
-
J. Ma, J. Huang, S. Liu, J. Luo, and L. Jing, “A self-attention legendre graph convolution network for rotating machinery fault diagnosis,” Sensors, Vol. 24, No. 17, p. 5475, 2024, https://doi.org/10.3390/s24175475
-
F. M. Bianchi, D. Grattarola, L. Livi, and C. Alippi, “Graph neural networks with convolutional arma filters,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 44, No. 7, pp. 1–1, Jan. 2021, https://doi.org/10.1109/tpami.2021.3054830
-
J. Hu, L. Shen, S. Albanie, G. Sun, and E. Wu, “Squeeze-and-Excitation Networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 42, No. 8, pp. 2011–2023, 2020, https://doi.org/10.1109/tpami.2019.2913372
-
L. Tarricone and M. Mongiardo, “A stable and efficient admittance method via adjacence graphs and recursive thresholding,” IEEE Transactions on Microwave Theory and Techniques, Vol. 49, No. 10, pp. 1750–1756, Jan. 2001, https://doi.org/10.1109/22.954780
-
S. Chatterjee, “Matrix estimation by universal singular value thresholding,” The Annals of Statistics, Vol. 43, No. 1, pp. 177–214, Feb. 2015, https://doi.org/10.1214/14-aos1272
-
H. Li, L. Liu, and Q. Wu, “Physics-guided Chebyshev graph convolution network for optimal power flow,” Electric Power Systems Research, Vol. 245, p. 111651, Aug. 2025, https://doi.org/10.1016/j.epsr.2025.111651
-
L. Liao et al., “An improved dynamic Chebyshev graph convolution network for traffic flow prediction with spatial-temporal attention,” Applied Intelligence, Vol. 52, No. 14, pp. 16104–16116, 2022, https://doi.org/10.1007/s10489-021-03022-w
-
Y. Ganin and V. Lempitsky, “Unsupervised domain adaptation by backpropagation,” in International Conference on Machine Learning, pp. 1180–1189, 2015.
-
B. Sun and K. Saenko, “Deep coral: correlation alignment for deep domain adaptation,” in Lecture notes in computer science, Cham: Springer International Publishing, 2016, pp. 443–450, https://doi.org/10.1007/978-3-319-49409-8_35
-
T. Li, Z. Zhou, S. Li, C. Sun, R. Yan, and X. Chen, “The emerging graph neural networks for intelligent fault diagnostics and prognostics: A guideline and a benchmark study,” Mechanical Systems and Signal Processing, Vol. 168, p. 108653, Apr. 2022, https://doi.org/10.1016/j.ymssp.2021.108653
-
T. Li, Z. Zhao, C. Sun, R. Yan, and X. Chen, “Domain adversarial graph convolutional network for fault diagnosis under variable working conditions,” IEEE Transactions on Instrumentation and Measurement, Vol. 70, pp. 1–10, Jan. 2021, https://doi.org/10.1109/tim.2021.3075016
-
X. Chen et al., “Transferability vs. discriminability: Batch spectral penalization for adversarial domain adaptation,” in International Conference on Machine Learning, pp. 1081–1090, 2019.
-
A. Ding, Y. Qin, B. Wang, L. Guo, L. Jia, and X. Cheng, “Evolvable graph neural network for system-level incremental fault diagnosis of train transmission systems,” Mechanical Systems and Signal Processing, Vol. 210, p. 111175, Mar. 2024, https://doi.org/10.1016/j.ymssp.2024.111175
About this article

The research was supported by the Major Science and Technology Project of Guangxi Province of China [Grant Number Guike AA23062073], Guangxi Natural Science Foundation under [Grant No. 2025GXNSFBA069131], Guangxi Young Elite Scientist Sponsorship Program [GXYESS2025172].
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Changbo Lin and Xiaoyu Guo designed the study, conducted the experiments, and wrote the main manuscript text, the contributions of the two authors are consistent, and they are the co-first authors of this article. Enyong Xu contributed to the data analysis. Lidong Liang provided critical revisions to the manuscript. Zhenzhen Jin supervised the project and coordinated the overall research. All authors reviewed and approved the final manuscript.
The authors declare that they have no conflict of interest.
