Abstract
Maintenance optimisation remains a persistent challenge in asset-intensive industries due to the combined uncertainties of failure behaviour and the economic consequences of strategy selection. Traditional decision frameworks typically rely on static cost comparisons or rule-based policies, which do not adequately reflect how hazard rates evolve across different lifecycle stages. This limitation creates a critical gap in linking risk-based reliability analysis with cost-driven evaluation, leaving decision makers without a robust basis for aligning maintenance strategies to both asset condition and economic impact. The objective of this study is to develop and test a framework that integrates hazard rate modelling with cost-based analysis to guide optimised maintenance decision-making. The approach applies simulation-based methods using Weibull distributions to characterise hazard rates across infant, random, and wear-out phases. Strategy performance is then evaluated through a process of normalisation and binning, which enables comparability across heterogeneous datasets and accounts for differences in data richness. Opportunity cost is introduced as the central decision metric, capturing the economic penalty incurred when a suboptimal strategy is implemented under specific hazard conditions. Findings reveal that no maintenance strategy is universally superior across all conditions. Corrective maintenance is viable only in low-hazard situations, but quickly becomes economically untenable as hazard rates increase. Time-based maintenance consistently demonstrates effectiveness in predictable environments and dominates in wear-out stages where escalating risk demands proactive intervention. Condition-based maintenance proves particularly valuable in situations where monitoring can offset uncertainty, offering a cost-effective balance between reactivity and prevention. Importantly, the results show that the framework is flexible: it remains meaningful in data-scarce contexts, where transparent assumptions allow useful insights, while in data-rich scenarios it produces stable parameter estimates and clearer economic benchmarks. This study contributes to the academic literature by bridging the gap between reliability modelling and economic evaluation. By integrating hazard functions with opportunity cost benchmarking, it advances beyond static cost comparisons to a dynamic, lifecycle-aware assessment of strategy performance. Practically, the framework provides maintenance managers with a transparent and adaptable decision-support tool that clarifies both when a strategy is most effective and what is lost when the wrong choice is made. In doing so, it enhances the ability of organisations to make defensible, data-informed decisions that minimise risk and maximise economic efficiency in asset management.
1. Introduction
Failure analysis is a cornerstone of effective engineering asset management, playing a crucial role in enhancing asset reliability, minimizing downtime, reducing production losses, and optimizing maintenance strategies. In addition to a macro-level perspective in engineering asset management, a detailed examination of specific failure modes can provide more profound insights into system performance and reliability. By understanding failures at this detailed level, organisations can not only boost operational efficiency and safety but also strengthen regulatory compliance and risk, informed decision-making. Importantly, when failures are systematically monitored and analysed, they can significantly drive down maintenance costs [1].
Complementary to failure analysis, a comprehensive understanding of maintenance costs is essential for informed maintenance decision-making. Proactive assessment of failure mode, considering both likelihood and consequence, enables organizations to allocate resources more effectively and reduce unnecessary expenditure [2]. Maintenance costs encompass all activities required to preserve or restore the function of assets, and their effective management is vital for maintaining operational continuity, extending asset lifespans, and mitigating unplanned downtimes. As engineering assets increasingly become viewed as profit, generating entities rather than cost centers, maintenance has taken on a more strategic role within industrial operations [3, 4]; thus the focus is on economic opportunity cost in this study.
Selecting an appropriate maintenance strategy is a pivotal element of the decision-making process. Over time, industries have not only diversified their maintenance approaches but have also witnessed the evolution of these strategies in response to technological advancements and operational demands [2]. According to Crespo Márquez, et al. [5], maintenance decision-making can be structured into two key phases: strategy definition and strategy implementation. The formulation of maintenance objectives, typically aligned with an organization’s broader business goals, guides the selection of suitable strategies [2]. Successful implementation, in turn, reflects an organisation’s capability to overcome practical challenges and achieve cost efficient maintenance execution.
Given the complexity of modern engineering systems and the imperative to maximise system uptime, prioritizing failure modes and aligning maintenance strategies with asset criticality is essential. Crespo Márquez, et al. [5] advocate for defining multiple, risk, aligned maintenance strategies where criticality is assessed based on defined risk profiles.
Failure analysis itself often involves categorizing failure events into distinct modes [6], which are then evaluated according to risk profiles derived from their probability of occurrence (failure rate) and potential consequences (e.g., total loss). A wide range of techniques has been developed to support this process, broadly classified into deterministic and probabilistic methods [7]. While deterministic methods are grounded in fixed assumptions and offer simplicity, they often fall short in capturing the inherent randomness and complexity of real, world systems. Probabilistic approaches, by contrast, incorporate uncertainty into modelling, allowing for more realistic and flexible analysis of system behaviour [7].
Probabilistic methods can further be divided into analytical and simulation-based approaches. Analytical methods are well, suited to small, scale systems due to their direct application and computational efficiency [8]. However, as system complexity increases, especially in environments with numerous interdependent components, analytical models become increasingly difficult to construct and interpret [9]. Moreover, many analytical techniques struggle to accurately represent the dynamic nature of real, world systems, where failure probabilities shift over time due to operational and environmental factors. For such scenarios, time, dependent simulation-based modelling approaches are needed to ensure accuracy and reliability in assessments [10].
In essence, while analytical methods remain valuable for simple systems with stable failure behaviours, their assumptions and limitations make them less suitable for large, complex systems where variability and interdependence dominate. Simulation- based probabilistic methods offer a more scalable and adaptable alternative, particularly when addressing the evolving reliability profiles of modern engineering assets. To address these challenges in modelling complex systems, simulation- based methods leverage statistical distributions that attempt to realistically represent failure behaviours and time, to, failure patterns. In event failure analysis, various simulations methods are used to model the time to failure, failure rates, and reliability of systems. Some of the most common distributions used in failure analysis to model the time to failure are Normal (Gaussian) Distribution, Exponential Distribution, Weibull Distribution, Poisson Distribution, Log, Normal Distribution, Gamma Distribution, Inverse Gaussian Distribution. Their usage, parameters and common applications, along with case study examples, are depicted in Table 1.
Table 1Common probability distribution methods applied in the study of event failure analysis
Distribution | Usage | Failure rate behaviour | Key parameters | Common applications and case study examples |
Normal (Gaussian) | Symmetric failure distributions | Bell, shaped curve | (mean), (std. dev.) | Lifespan of products, wear and degradation [11] |
Exponential | Random failure Process | Constant () | (rate) | Electronic components, software reliability [12] |
Weibull | Wear - out, aging effects | Varies () | Β (shape), (scale) | Mechanical components, fatigue analysis [13] |
Poisson | Models the number of events in a fixed interval of time or space | Constant rate over time | (average rate) | System failures, breakdowns, rare events [14] |
Log, Normal | Skewed failure time distributions | Decreasing over time | (log mean), (log std. dev.) | Electronic devices, chemical failures [15] |
Gamma | Multi, phase failure processes | Varies with k | (shape), (rate) | Repairable systems, waiting times [16] |
Inverse Gaussian | First, passage failure times | Decreasing over time | (mean), (scale) | Biomedical applications, stock failures [17] |
Simulation, in the context of engineering asset management, serves as a powerful tool for modelling the dynamic behaviour of assets and their failure patterns over time. By replicating the operation of real, world systems, such as machinery, infrastructure, or production lines, simulation enables researchers and maintenance engineers to gain deeper insights into how these systems evolve under different operating conditions and maintenance strategies. Whether performed manually or using a computer, it involves creating an artificial history of a system based on the current conditions and analysing that history to gain insights into how the actual system functions. Simulation models are constructed by formalising assumptions about system behaviour through explicit mathematical formulations, rule-based logic, and abstract representations that govern interactions among system components. Once a model is developed and validated, it can be used to explore various “what, if” scenarios, allowing users to predict the impact of potential changes before implementing them in the real world. This makes simulation a valuable tool for both analysing existing systems and designing new ones. Simulation can be particularly useful in the early stages of system development [18], helping designers evaluate different configurations before committing to costly real, world implementation. Many real - world systems are inherently complex, requiring comprehensive approaches to understand and manage their performance and reliability. In such cases, computer-based simulations are used to mimic system behaviour over time. These simulations generate data as if the actual system were being observed, allowing researchers to estimate performance measures and make informed decisions [19].
This paper focuses on creating a simulation of a mining site operation based on firm’s historical data. The simulation is basically based on the different risk profiles drafted with the assistance of quantitative risk assessment. The simulation provides the ability to create a “control-treatment” setup e.g., where the control might be a context in which a corrective maintenance regime exists, and the counterfactuals or treatments could be preventative maintenance or condition- based maintenance. In such a framing, an economic analysis can be applied wherein the opportunity cost is simply the relative maintenance cost difference between the control and treatment over a certain period. The economic analysis when performed on different risk (failure likelihood and impact) profiles across different failure modes, reveals the relationship between the maintenance strategy that minimises the opportunity costs (compared to the control) and the risk. Moreover, while industries often possess the necessary tools and techniques to identify and implement effective maintenance strategies, they frequently overlook the critical aspect of aligning these strategies with their available maintenance budgets. This misalignment can lead to deferred maintenance, where essential upkeep is postponed due to budget constraints, ultimately resulting in higher costs and increased equipment downtime [2]. Organisations are generally bounded by an annual maintenance budget which becomes a constraint while applying the maintenance strategies [2].
In this study, a control - treatment simulation is particularly relevant in addressing the problem of identifying the optimal maintenance strategy for particular contexts, because it allows the construction of counterfactual worlds with parameters that are underpinned by real world historical failure and maintenance data to predict asset performance and reliability under different maintenance regimes. This predictive capability is useful when selecting and evaluating maintenance strategies (e.g., corrective, preventive, or condition- based), as it provides a risk, informed, data, driven basis for decision-making. By simulating various failure scenarios and maintenance interventions, it is possible to assess their long-term impact on asset availability, cost, and risk. Static or purely analytical models may not adequately capture these effects, particularly in complex systems with time-varying failure rates such as those examined in this study.
The paper reviews existing research across three key themes: simulation studies in maintenance decision-making, hazard rate models for lifecycle assessment, and the use of opportunity cost in guiding strategic choices. This sets the theoretical foundation and highlights the gaps that the present study addresses. The paper uses maintenance work order data and downtime from a gold mining company in Australia as a case study. Three critical failure modes of Bearings, Liners, and Chutes are considered providing the basis for reliability modelling and cost simulation. This study employs a simulation-based framework that integrates hazard rate modelling with economic evaluation of maintenance strategies. Failure times for multiple components are characterised using Weibull distributions, allowing hazard functions to be estimated across infant, random, and wear-out phases of the asset lifecycle. Simulated data are then normalised and binned to ensure comparability across heterogeneous datasets. Within each hazard bin, the costs of corrective, condition-based, and time-based maintenance are evaluated, and opportunity cost is introduced as the decision metric to quantify the penalty of suboptimal strategy selection. This combination of hazard-driven reliability analysis and cost benchmarking provides a dynamic basis for comparing strategy performance under varying lifecycle conditions.
1.1. Simulation study in maintenance decision-making
A simulation study is valuable because it helps researchers and decision, makers understand complex systems, test different strategies, and optimize outcomes without real, world risks or costs. It’s especially useful in fields like aerospace, manufacturing, and robotics [20], where real, world testing can be expensive or dangerous. Simulations allow for safe experimentation, helping to evaluate policies, improve resource allocation, and enhance efficiency. They also handle uncertainty and randomness, making them ideal for areas like finance, logistics, and engineering. By integrating real, world data, simulations improve accuracy, speed up testing, and support better decision-making. In maintenance, for example, they help compare corrective, preventive, and condition- based strategies to find the most cost, effective approach [21]. Within the mining sector, simulation-based studies are commonly used to evaluate proposed operational strategies by representing the time-varying, uncertain, and system-level behaviour of mining processes, thereby informing capital and operational investment decisions, including applications in underground environments [22-27]. There have been studies in the past showcasing the application of simulation study in the field of risk assessment and maintenance management to assist engineers and maintenance managers in the maintenance decision - making [28-32].
Talking about the application of simulation study in maintenance decision-making, Koops [33] presents a simulation, supported prescriptive analytics framework that integrates probabilistic cost-benefit analysis for maintenance decision - making. The study employs a Wiener process degradation model to simulate equipment deterioration and utilizes Monte-Carlo simulations to evaluate various maintenance strategies under uncertainty. This approach enables the assessment of maintenance options based on their potential costs and benefits, facilitating informed decision-making in maintenance planning. Kono and Haneda [34] present an agent-based simulation model designed to support maintenance strategy design and decision-making. Through the development of an agent-based maintenance simulator to support planning activities, the approach provides organisations with a configurable modelling capability that can be adapted across different operational contexts. From an industrial perspective, the model can also help in the quantification of total costs associated with different maintenance policies and computes productivity and key maintenance indexes. Gosavi and Gosavi [35] present a simulation- based digital twin framework that integrates reinforcement learning, specifically actor, critic algorithms, for maintenance scheduling in risk, prone production lines. The digital twin serves as a virtual representation of the physical production system, enabling real, time data assimilation and decision-making. By leveraging reinforcement learning, the model adapts maintenance schedules dynamically, optimizing for reduced downtime and improved system reliability.
Among various simulation methodologies employed in maintenance decision - making, discrete event simulation (DES) has emerged as a dominant approach due to its ability to accurately model the dynamic behaviour of complex systems over time. Banks [19] formally defines DES as “Discrete event simulation models the system as it evolves over time by representing it as a sequence of events that change the state of the system”. Meissner, et al. [36] present a DES framework tailored for the aviation industry to develop prescriptive maintenance strategies. The study focuses on post, prognostics decision - making, integrating prognostic health management (PHM) data to inform maintenance scheduling and resource allocation. By simulating various maintenance scenarios, the framework evaluates the impact of different strategies on aircraft availability and maintenance costs. The results demonstrate that the DES approach enables more informed and effective maintenance planning, leading to improved operational efficiency and reduced downtime. Another modular framework employing DES has been introduced by Pohya, et al. [37] to evaluate aircraft technologies, maintenance strategies, and operational decision-making throughout the product life cycle. The framework represents the complete asset lifecycle, beginning with order placement and extending through sustained operation, maintenance activities, and end-of-life disposition. It enables comparative evaluation of alternative decision strategies with respect to asset condition performance, energy utilisation efficiency, and system-level cost effectiveness. The modularity of the framework ensures adaptability to different scenarios, enabling stakeholders to analyse the effects of maintenance strategies and operational procedures on system performance and costs.
In environments like manufacturing and mining, where maintenance activities are driven by unpredictable failures and resource constraints, DES offers a practical framework for evaluating system performance under various maintenance policies. DES has previously been used in mining applications to assess how alternative maintenance work packages influence system reliability and lifecycle cost behaviour by Turan and Golbasi [38]. In that work, maintenance decisions are modelled within a stochastic optimisation framework, with performance objectives focused on improving overall availability while controlling maintenance-related costs across the planning horizon. By simulating different maintenance scenarios, the research provides insights into how varying maintenance strategies can influence the reliability and economic performance of mining operations. Askari-Nasab, et al. [39] present a simulation, optimization framework that integrates discrete event simulation (DES) with optimization techniques to enhance mine operational planning. The study focuses on truck, shovel systems in open, pit mines, modelling the complex interactions between equipment, haulage routes, and operational constraints. By simulating various operational scenarios, the framework aids in identifying optimal strategies that improve productivity and reduce operational costs. The approach demonstrates the effectiveness of DES in capturing the stochastic nature of mining operations and supporting decision-making processes. Ben-Awuah, et al. [40] explore the application of DES in hierarchical mine production scheduling. The study emphasizes the integration of DES into long, term and short, term planning processes to evaluate the impact of various scheduling decisions on mine productivity and resource utilization. By simulating different production scenarios, the research highlights how DES supports the analysis of process constraints, informed allocation of resources, and enhancement of operational performance within mining systems. Soto, et al. [41] present a DES model to examine planning of mine development activities at Codelco's New Mine Level project. The study focuses on evaluating different development scenarios to optimize resource allocation and scheduling. By simulating various operational strategies, the model aids in identifying the most efficient approaches to enhance productivity and reduce development time in underground mining operations. Tarshizi, et al. [42] introduce an advanced approach employing DES and animation to evaluate and enhance emergency evacuation strategies in underground mines. The study models various evacuation scenarios, considering factors such as escape routes, miner locations, and emergency response times. The findings underscore the effectiveness of DES in improving safety protocols and emergency preparedness in mining environments.
While existing literature has extensively applied DES to model and optimize mining operations, the primary emphasis has often been on aspects such as production scheduling, evacuation planning, equipment allocation, and general maintenance workflow evaluation. Much of this work concentrates on system, level efficiency and operational logistics, using simulation to test predefined scenarios or assess throughput and resource utilization. In studies that incorporate maintenance considerations, the typical approach involves estimating costs or comparing fixed strategies under different operating conditions. However, these models rarely incorporate failure dynamics at a granular level, nor do they address maintenance decision-making from a hazard, driven or failure, adaptive perspective. The simulation logic tends to assume maintenance policies in advance rather than letting them emerge from a dynamic understanding of component reliability or risk. As a result, the potential for simulation to support real, time, data, informed strategy optimization, particularly based on evolving hazard rates and cost impacts, remains underutilized in the existing literature. In contrast, the present research introduces a hazard, cost simulation framework that integrates failure time modelling, hazard rate estimation (based on Weibull distribution), and dynamic strategy selection rooted in cost optimization and phase classification. By simulating individual failure behaviours and linking them to economic impacts, this approach goes beyond traditional DES applications by enabling risk, informed, data, driven maintenance decision-making, specifically tailored to asset degradation characteristics. Furthermore, the framework incorporates a verification loop to validate strategy effectiveness, an element rarely emphasized in existing simulation studies. This positions the current work as a more granular, failure, centered, and economically grounded approach to maintenance strategy design in complex, resource, intensive systems like mining operations.
1.2. Hazard rate models in maintenance decision-making
The hazard function describes the instantaneous risk of failure and is central to survival and reliability analysis. The Weibull distribution, due to its flexibility, is commonly used in modelling hazard rates in engineering systems [43]. When the shape factor 1, the hazard rate decreases over time (infant mortality); when 1, it remains constant (random failures); and when 1, it increases (wear-out). The use of hazard rate models in maintenance decision-making has undergone significant evolution over the past decades. Early foundational work, such as the Proportional Hazards Model (PHM) proposed by Cox [44], enabled the linking of failure risks to influencing covariates. More recent studies have advanced PHM applications by integrating machine learning techniques for covariate prioritization and dynamic weight estimation, thus enhancing predictive maintenance capabilities [45]. However, these approaches rely heavily on the availability and accuracy of external covariates, which may not always be practical in industrial settings. In parallel, the development of Generalized Renewal Processes (GRPs) addressed the need to model imperfect maintenance actions, incorporating concepts like virtual age and restoration factors to capture the realistic impact of repairs on system reliability [46]. While powerful, GRPs often involve high mathematical complexity and data intensity, limiting their direct applicability in real, time decision environments. More recently, research attention has shifted toward Condition-based Maintenance (CBM) strategies that employ dynamic hazard thresholds for triggering maintenance interventions [47]. These approaches allow maintenance actions to adapt to the evolving risk profile of assets, offering a more responsive and cost, efficient alternative to traditional time- based maintenance plans.
Looking at the application of hazard rate models in maintenance decision-making, Wu and Clements-Croome [48] investigate maintenance policy optimisation under different operating schedule scenarios. They introduce models that incorporate hazard rates to determine the most cost, effective maintenance intervals. The study emphasizes the importance of aligning maintenance strategies with the operational patterns of equipment to minimize downtime and costs. Wu, et al. [49] introduce a maintenance optimisation framework in which reliability risk reduction, expressed through hazard rate behaviour, is jointly evaluated alongside energy usage considerations. The study introduces an age, centered maintenance policy that integrates the system’s hazard rate function with energy consumption models. By formulating a bi, objective optimization problem, the framework seeks to identify maintenance schedules that balance the trade, off between reducing failure risks (as represented by hazard rates) and minimizing energy usage. The findings confirm the practical viability of the presented approach in achieving cost, effective maintenance strategies that account for both reliability and energy efficiency. Duan, et al. [50] propose an integrated framework that combines health measure predictions with optimal maintenance policies using the Proportional Hazards Model (PHM). The study focuses on systems subject to condition monitoring, where the hazard rate is influenced by covariates representing the system's health state. By integrating PHM into the maintenance decision-making process, the framework enables dynamic adjustment of maintenance actions based on the evolving condition of the equipment. This approach enhances the effectiveness of maintenance strategies by accounting for real, time health information, leading to improved system reliability and cost efficiency. Samrout, et al. [51] present a hazard rate- based framework that integrates preventive and corrective maintenance within the Proportional Hazard Model (PHM). Unlike many conventional approaches that treat corrective maintenance independently, this work considers the residual effect of past failures and repair actions on the evolving hazard rate of components. Covariates are used to capture the cumulative influence of maintenance history, allowing the model to adaptively reflect degradation and recovery patterns over time. Optimization techniques such as Ant Colony Optimization and Genetic Algorithms are applied to identify cost, effective maintenance schedules.
While hazard rate modelling has played a pivotal role in guiding maintenance decision-making, by capturing the dynamic risk of failure over time, there remains a need for models that accurately represent the full lifecycle behaviour of systems, particularly those exhibiting non, monotonic failure patterns. In this context, the application of the Weibull distribution has gained prominence as a versatile tool for modelling the characteristic phases of the bathtub, shaped hazard rate, enabling a more nuanced understanding of early, life failures, useful life, and wear-out periods. The following studies explore how Weibull-based approaches have been employed to represent this behaviour and support more effective, phase, specific maintenance planning. Xie and Lai [52] introduce the additive Weibull model as an extension of the standard Weibull distribution to effectively model lifecycle-dependent hazard rate behaviour. The additive Weibull model combines two Weibull distributions, allowing for greater flexibility in capturing the decreasing, constant, and increasing failure rate phases characteristic of the bathtub curve. The authors demonstrate the model's applicability through analytical studies and real, life data, highlighting its potential in reliability analysis and maintenance decision-making. Belyi, et al. [53] present a Bayesian approach to modelling failure rates, considering both increasing and bathtub-shaped hazard functions. The proposed methodology employs an extended gamma process formulation to provide a nonparametric representation of monotonic hazard rate behaviour. It also allows for the incorporation of prior knowledge and observed data, facilitating more informed maintenance decisions. The study demonstrates how Bayesian models can optimize preventive maintenance schedules by accurately estimating failure probabilities. Assis, et al. [54] introduces the generalized q‐Weibull distribution, a flexible model capable of representing various hazard rate behaviours, including the classic bathtub shape characterized by decreasing, constant, and increasing failure rates. The authors analyse the mathematical properties of the q‐Weibull model, demonstrating its ability to unify different failure rate patterns within a single framework. The paper includes analytical developments, graphical illustrations, and a practical application example, highlighting the model’s effectiveness in reliability analysis and maintenance decision-making contexts. The q‐Weibull model's versatility in capturing the entire spectrum of hazard rate behaviours makes it a valuable tool for maintenance planning and reliability assessment. By accommodating the bathtub, shaped hazard function, it allows for more accurate modelling of component lifecycles, leading to improved maintenance strategies and resource allocation.
While a range of statistical models exist for representing failure behaviour, as described above, the selection of an appropriate distribution must align with the objective of the analysis. In this study, the Weibull distribution was selected because it enables direct representation of varying hazard rate behaviour within a single parametric form, which supports lifecycle-based modelling. This is particularly relevant for the proposed framework, where maintenance strategies are evaluated across different phases of asset operation. The objective of this study is not to identify the statistically optimal distribution for failure modelling, but to develop a decision-oriented framework that links hazard behaviour with economic evaluation. From this perspective, the Weibull distribution provides a consistent and interpretable basis for modelling hazard rate evolution across failure modes with varying data availability. Accordingly, its selection is guided by its suitability for lifecycle representation and integration within the proposed decision framework.
1.3. Opportunity cost in maintenance decision-making
The integration of economic considerations into maintenance decision-making has long been recognized as essential, particularly through the concept of opportunity cost. Sillivant [55] emphasized that the “lost opportunity cost” associated with downtime represents a critical but often underappreciated factor when evaluating maintenance approaches. This insight was important in highlighting that maintenance decisions extend beyond direct expenditures to include the economic consequences of foregone production or delayed availability. However, while Sillivant [55] work identified opportunity cost as a key dimension, it did not establish a formal link between hazard rate functions, maintenance strategies and opportunity cost modelling. As a result, the analysis remained largely conceptual, leaving open the challenge of embedding opportunity cost into a dynamic, hazard, driven framework.
Building on this economic perspective, Peimbert-Garcia, et al. [56] introduced a model that explicitly incorporated both opportunity cost and infant mortality costs into maintenance decision-making. Their work quantified the significant financial impact that early, life failures can impose, particularly in industrial contexts where production interruptions translate directly into economic losses. While this study advanced the discussion by embedding economic penalties into maintenance evaluation, it primarily focused on the initial phase of the asset lifecycle. Consequently, the model provided limited guidance on how costs evolve across the entire lifecycle, especially during the random failure and wear-out phases where hazard rates behave differently.
More recently, Frederiksen, et al. [57] examined the marginal benefits of predictive maintenance by comparing them against existing preventive strategies. Their contribution was to evaluate predictive approaches not only in terms of reliability outcomes but also through a cost-benefit lens. This comparison underscored the potential of predictive maintenance to deliver incremental economic gains beyond conventional preventive methods. However, their study did not fully integrate the impact of hazard rate dynamics into the cost-benefit analysis. Without explicitly modelling how hazard rate influences both failure likelihood and cost variability, the analysis risks overlooking the conditions under which predictive maintenance delivers its greatest advantages.
Byon and Ding [58] also contributed significantly to the discussion by comparing static, scheduled maintenance strategies with dynamic, hazard, informed approaches. Their findings revealed that dynamic strategies can achieve substantial improvements in both reliability and cost outcomes compared to fixed schedules. This highlighted the potential efficiency of adapting maintenance to the evolving risk profile of assets rather than adhering to rigid time intervals. Nonetheless, their study remained narrowly focused on cost-benefit trade-offs and did not incorporate broader measures of opportunity cost. As such, while it demonstrated the operational superiority of dynamic strategies, it did not fully capture the economic consequences of suboptimal decisions.
The present study addresses this gap by combining Weibull- based hazard modelling with probabilistic cost simulation across multiple strategies, Corrective, Condition-based, and Time-based Maintenance. More importantly, it reframes maintenance evaluation in terms of opportunity cost, quantifying the economic regret of selecting a suboptimal strategy across different phases of the asset lifecycle. In doing so, it extends the earlier literature from cost - benefit comparisons toward a more holistic decision, support framework that explicitly captures the trade, offs between hazard, lifecycle phase, and economic outcomes.
Opportunity cost is a fundamental concept in economic decision-making, representing the value of the best alternative that is not selected when a decision is made. In the context of maintenance management, this translates to the economic consequence of choosing one maintenance strategy over another when multiple feasible options exist. In practical terms, maintenance decisions often involve selecting between strategies such as Corrective Maintenance (CM), Condition-Based Maintenance (CBM), and Time-Based Maintenance (TBM), each of which may be suitable under different operating conditions. While traditional approaches focus on identifying the lowest-cost strategy, they often overlook the economic implication of selecting a suboptimal alternative. This becomes particularly relevant in environments where failure behaviour and associated risks evolve over time. In this study, opportunity cost is used as a decision indicator to capture the economic penalty associated with such suboptimal choices, enabling maintenance strategies to be evaluated relative to the best available alternative under given conditions. The detailed formulation and its integration within the hazard-based simulation framework are presented in Section 4.
The present study extends prior work on hazard- based maintenance optimization, particularly the contributions of Drent, et al. [59] and Zheng, et al. [60], which form the closest methodological antecedents to this research. Drent, et al. [59] developed a Semi, Markov decision process model to design control, limit policies for condition-based maintenance (CBM). Their study represented an important step in demonstrating how hazard rate information can guide maintenance interventions, moving away from static preventive schedules. They also compared the costs of optimal versus suboptimal policies, offering a valuable benchmark for evaluating CBM performance. However, their focus was limited exclusively to CBM strategies, without examining how corrective maintenance (CM) or time- based maintenance (TBM) might behave under similar hazard, driven decision frameworks. Moreover, while they provided cost comparisons, their framework did not incorporate an explicit opportunity, cost metric, that is, a measure of the economic regret associated with choosing a suboptimal strategy relative to the best available alternative. Zheng, et al. [60] advanced the field further by introducing a proportional hazards model (PHM) to monitor system health and guide condition- based policies. Their work integrated dynamic hazard, rate thresholds for initiating actions and allowed for multiple forms of intervention, including partial and full replacements. This provided a more flexible framework for modelling the diversity of real, world maintenance actions. Nonetheless, their study still faced several limitations. First, it remained centered on single, component systems, which restricted its applicability to the complex, multi, component realities of industrial operations. Second, like Drent, et al. [59], their work did not develop an explicit opportunity, cost perspective, meaning that while strategies were evaluated in terms of hazard and cost structures, the economic penalty of misalignment was not captured. Finally, their cost modelling was simplified, without exploring the variability of cost distributions across different lifecycle phases.
The present research addresses these limitations by extending the foundations laid by Drent, et al. [59] and Zheng, et al. [60] in three key directions. First, rather than focusing only on CBM, this study considers all three major strategies, CM, CBM, and TBM, simultaneously within a hazard-based framework. This comparative approach allows for a more comprehensive evaluation of maintenance policies across the asset lifecycle. Second, the research introduces opportunity cost as a unifying decision indicator, reframing strategy evaluation from absolute cost comparisons to the economic regret incurred when a non, optimal choice is made. This innovation provides a transparent and intuitive lens for decision - making that neither of the earlier studies explicitly considered. Third, the framework incorporates probabilistic cost modelling using Weibull distributions with phase, specific parameters, allowing cost variability to be tied directly to hazard intensity and lifecycle stage. This extends beyond the simplified cost assumptions of earlier work, offering a richer and more realistic representation of the economic dimension of maintenance decisions.
In this way, the study does not replace but rather builds upon the work of Drent, et al. [59] and Zheng, et al. [60] combining the strengths of hazard- based optimization and simulation while addressing the identified gaps. It extends their pioneering ideas into a broader decision, support methodology that is both lifecycles, aware and economically transparent. In relation to this evolving body of work, the current research differs in a number of important ways. Unlike PHM-based frameworks that depend on covariate modelling, the present study directly simulates hazard rate evolution using Weibull, distributed failure times, eliminating the need for external condition monitoring data. Although the current research assumes perfect maintenance for simplicity, like basic renewal processes, it establishes a foundation that could later accommodate GRP-based imperfect maintenance modelling. Most notably, this research builds upon recent CBM advancements by not only using dynamic hazard thresholds for maintenance classification but also integrating an opportunity cost notion into the decision-making framework. This approach, combining hazard rate evolution, economic assessment, and strategy validation within a single simulation environment, fills a critical gap in existing literature where hazard- based decision triggers often lack opportunity cost considerations for firm, level decision - making. Consequently, the proposed framework positions itself as an advancement toward more practical, simulation, driven maintenance optimization, offering both theoretical and applied contributions to the field.
1.4. Methodological approach to maintenance decision-making
Building on the identified research gaps in hazard-based maintenance modelling and economic evaluation, this study introduces a structured framework that integrates lifecycle reliability behaviour with cost-driven decision-making. While prior studies have addressed elements of hazard modelling or maintenance cost optimisation independently, there remains a lack of approaches that explicitly connect time-dependent failure behaviour with economic consequences in a unified and operationally applicable manner. In response, the present study develops a simulation-based methodology that enables maintenance strategies to be evaluated dynamically across lifecycle phases, rather than through static or rule-based comparisons. This study makes four specific methodological contributions to maintenance decision-making:
1) Hazard-driven lifecycle–economic evaluation framework. A simulation-based methodology that extends traditional risk assessment by integrating Weibull-based hazard modelling with economic evaluation, enabling maintenance strategies to be assessed as a function of time-varying failure behaviour across lifecycle phases.
2) Lifecycle-synchronised simulation and hazard modelling. A structured approach that combines phase-wise Weibull modelling, large-scale failure simulation, and rescaling onto a common operational horizon, allowing heterogeneous failure modes to be analysed within a unified lifecycle framework.
3) State-dependent strategy evaluation using hazard normalisation and binning. A two-step transformation where hazard rates are first normalised to a dimensionless scale and then discretised into bins, enabling consistent, localised comparison of maintenance strategies across different failure modes and lifecycle conditions.
4) Opportunity cost–based decision metric with probabilistic cost modelling. A formulation that integrates Weibull-based cost simulation with opportunity cost benchmarking to quantify the economic regret associated with suboptimal strategy selection, providing a transparent and decision-relevant evaluation metric under uncertainty.
Collectively, these contributions establish a coherent framework that bridges reliability modelling and economic decision-making in a way that is both methodologically structured and practically applicable. By linking hazard rate evolution with probabilistic cost behaviour and regret-based evaluation, the study moves beyond conventional maintenance optimisation approaches that rely on static cost comparisons or predefined policy rules. Importantly, the significance of these contributions lies not only in the individual components, but in their integration within a single decision-oriented methodology. The framework enables maintenance strategies to be evaluated in relation to lifecycle dynamics, uncertainty in cost outcomes, and the economic consequences of suboptimal decisions. As such, it provides a transparent and adaptable decision-support tool capable of informing maintenance policy across varying data conditions and operational contexts.
2. Data
The work presented in the paper is based on the case study of a gold mining company in Australia. The industry failure data was collected from two different sources, one providing maintenance work order information and another providing downtime information. These were labelled ‘Selective work orders.xlsx’ and ‘Downtime.xlsx’ respectively. The raw data was recorded manually over different periods for different systems, downloaded in comma, separated value (CSV) format, and was initially analysed in MS Excel. Through this process, a new dataset was created which was largely tailored to this undertaking. The initial exploratory analysis using information originally from the ‘Downtime.xlsx’ client spreadsheet. The major focus was on extracting variables like failure modes, downtime associated with those failure modes and finally the downtime cost associated with each failure mode. As the industry manually records the data, it was difficult to find consistency in the data across the time frames as highlighted in Table 2.
Table 2Data summary
System | Time stamp |
Mill | January 2021 – October 2021 |
Crusher 1 | July 2021 – April 2022 |
Modular Crusher | January 2021 – April 2022 |
Nolans Crusher | January 2021 – April 2022 |
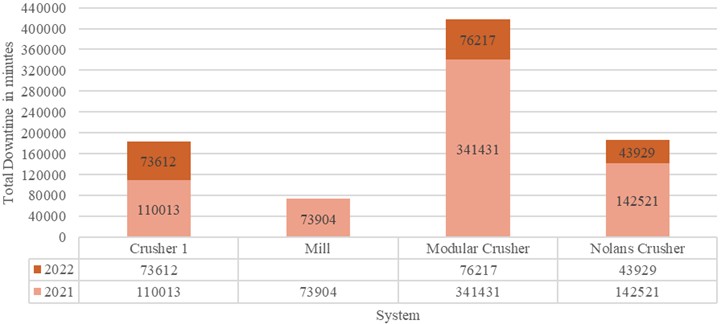
The identified critical system based on downtime from Table 2 is Modular Crusher as highlighted in Fig. 1, with its year-wise downtime bifurcation. The downtime history of individual systems presented in the Fig. 1 are in minutes.
Table 3 shows the different failure modes of all the equipment associated with the Modular Crusher system.
Some commonly observed failure modes were blockage of jaws, damaged belt, bogged conveyor, bearing failure, liners/bolts failure, oil and lubrication issues, chute issues, electrical issues, etc.
However, “Total Circuit” does not resemble any equipment but rather it was a qualitative choice made by the operator to record a downtime event. For instance, if a conveyor bearing fails and interrupts the entire circuit, some operators recorded this as a “Total Circuit” failure. From an asset criticality perspective, it had to be assigned to ‘conveyor’ otherwise it had no use. Some of the undefined failure modes were listed under “others”, and were omitted as they could not be processed.
Table 3Failure modes of all the equipment associated within the critical system
Critical system | Equipment | Failure modes |
Modular crusher | Crusher | Blocked jaw |
Grizzly bar breakdown | ||
Electrical fault | ||
Hydraulic leak | ||
Liners /bolts | ||
Motor breakdown | ||
Oil & lubrication | ||
Bins issue | ||
Maintenance | ||
Other | ||
CV 201 | Belt damaged | |
Chute issues | ||
Electrical fault | ||
Mechanical fault | ||
Bins issue | ||
Other | ||
Feeder | Blockage | |
Mechanical fault | ||
Bins issue | ||
Electrical fault | ||
Maintenance | ||
Liners/bolts | ||
Others | ||
Fines conveyor | Belt damaged | |
Conveyor bogged | ||
Electrical fault | ||
Truck delay | ||
Others | ||
Loader | Loader unavailable | |
Maintenance | ||
Hydraulic leak | ||
Low manning | ||
Others | ||
Product stacker | Conveyor bogged | |
Electrical fault | ||
Commissioning | ||
Others | ||
Reject stacker | Bearings failure | |
Belt damaged | ||
Blockage | ||
Conveyor bogged | ||
Electrical fault | ||
Maintenance | ||
Mechanical fault | ||
Liners/bolts | ||
Others | ||
Rock breaker | Hydraulic leak | |
Noise | ||
Others | ||
Screen | Bearings failure | |
Belt damaged | ||
Conveyor bogged | ||
Maintenance | ||
Electrical fault | ||
Liners/bolts | ||
Mechanical fault | ||
Oil & lubrication | ||
Blockage | ||
Screen mats | ||
Others | ||
Total circuit | Belt damaged | |
Blocked jaw | ||
Conveyor bogged | ||
Maintenance | ||
Commissioning | ||
Electrical fault | ||
Low manning | ||
Liners/bolts | ||
Mechanical fault | ||
Noise | ||
Screen mats | ||
Others |
Fig. 1Analysis of system downtime
3. A priori theory and hypothesis
Maintenance strategy performance can be framed as a function of the hazard rate , which describes the time-dependent risk of failure. Reliability theory suggests that different strategies are likely to dominate under different hazard conditions, depending on the balance between failure likelihood, preventive costs, and monitoring efficiency.
At very low hazard intensities, the expected cost of failures is minimal. In such conditions, Corrective Maintenance (CM) is likely to dominate, as the added fixed costs of preventive replacement or monitoring cannot be economically justified. As the hazard rate increases into the random operation zone, Condition-Based Maintenance (CBM) becomes more attractive, particularly when detection efficiency is high. Here, CBM balances modest monitoring costs with the significant savings achieved by converting a portion of expensive unplanned failures into cheaper planned interventions. Finally, in the high-hazard, wear-out phase, Time-Based Maintenance (TBM) is expected to outperform both CM and CBM, because preventive replacements substitute repeated costly failures with predictable and scheduled expenditures.
From these theoretical relationships, three directional hypotheses are derived:
1) H1: CM is expected to be more economically viable in low-hazard bins where failures are rare and preventive costs are unjustified.
2) H2: CBM is expected to minimise costs in moderate hazard conditions, particularly when detection efficiency is high.
3) H3: TBM is expected to outperform alternative strategies in high-hazard wear-out conditions, where preventive action becomes economically advantageous.
The above hypotheses are formulated as a priori theoretical expectations based on established hazard rate behaviour and general maintenance strategy characteristics. They are not intended as empirically validated claims, but rather as structured assumptions used to evaluate whether the proposed framework produces results consistent with expected lifecycle patterns. In this sense, they provide a foundational baseline for the study by linking the present work to established reliability theory, articulating what is expected in principle, while also serving as a benchmark against which the simulation results can be validated. Accordingly, the proposed methodology is not developed in isolation, but is explicitly designed to assess the alignment between empirical findings and these theoretical expectations.
4. Hazard rate approach to cost-driven maintenance decision-making
This study builds directly upon the foundation established in the earlier work published by the author [61] on multi-stage risk assessment framework, where equipment risk profiles were quantified by integrating failure likelihood, downtime severity, and economic consequences. The framework demonstrated how a structured, stage, wise evaluation could move maintenance decision-making beyond qualitative judgment, providing a transparent map of where risks accumulate within complex mining systems. However, while the multi, stage approach offered a comprehensive view of criticality, it largely operated at a macro level, identifying which systems and failure modes mattered most, but not yet exploring the finer dynamics of how maintenance strategies perform across the lifecycle of those failures. The present study takes that next step by embedding the principles of lifecycle reliability modelling and opportunity cost into the analysis. By linking hazard rate behaviour with simulated economic outcomes, it extends the earlier risk framework into a decision, oriented tool, capable of benchmarking maintenance strategies not just by their role in mitigating risk, but by the economic (opportunity cost) regret they may impose when chosen sub, optimally across different phases of the asset life.
The analysis began with a deliberate decision to work within the R environment, chosen for its balance of statistical strength and flexibility in visualization. A handful of core libraries became the backbone of the workflow: “dplyr” shaped the data into analysable form, “ggplot2” offered a platform to communicate results visually, “openxlsx” bridged the analysis with industry, standard spreadsheets, and “fitdistrplus” provided the tools for robust parametric distribution fitting. Recognizing the importance of reproducibility, every element of randomness was fixed with explicit seeds, ensuring that the results could be revisited and replicated with confidence.
With the computational foundation in place, attention shifted to the raw material of the study: failure data from three key modes, Bearings, Liners, and Chutes. These datasets carried the natural messiness of real operations, yet rather than over, cleaning, the decision was to respect their authenticity. Each set of times was taken as, is, acknowledging the truth they represented about operational performance. To align the analysis, a single operational horizon of 11,640 hours was imposed. This horizon served as a common canvas against which different failure behaviours could be compared and synchronized.
The choice of these particular failure modes was not arbitrary but rather an informed continuation of the earlier multi, stage risk assessment. In that framework, Bearings, Liners, and Chutes consistently emerged as high, priority contributors to overall system risk, either through their frequency of occurrence, the severity of downtime they imposed, or their influence on broader system reliability. Bearings, although represented by relatively few recorded failures, were highlighted as critical due to their direct link to unplanned stoppages and their potential to trigger cascading mechanical issues. Their inclusion here reflects not only their operational significance but also the need to demonstrate how lifecycle modelling can extend to data, scarce contexts. Liners, in contrast, were identified as components with a recurring pattern of wear, related failures, imposing significant downtime but also offering a sufficiently rich dataset for robust Weibull fitting. This made them ideal for exploring phase, wise lifecycle behaviour. Chutes were included because the earlier study revealed them as frequent yet often underestimated sources of disruption. While not central to core production in themselves, their failure had measurable ripple effects on material flow, validating their selection for deeper exploration. By carrying these three modes forward, the present study ensures continuity with the earlier risk framework while extending the analysis from which ‘failures matter most’ to ‘how maintenance strategies perform across their lifecycles’.
Modelling the behaviour of these failure modes required an appreciation of the asset lifecycle. Instead of treating the data as uniform, the failures were conceptually divided into three phases of the classic bathtub curve: infant mortality, random operation, and wear - out. In this framework, distinct phase splits are applied at three stages: Weibull parameter estimation, failure simulation, and hazard rate classification, each tailored to its specific modelling purpose. For parameter estimation, a 20-60-20 chronological split is used to capture early, mid, and late-life failure patterns from observed data, ensuring that estimated Weibull parameters reflect their respective lifecycle stages. Simulated failures are then generated using a 30-40-30 distribution across the infant, random, and wear-out phases. This approach increases the density of data in the high-risk early and late stages, which enhances the resolution of subsequent hazard-rate and cost evaluations where decision sensitivity tends to be higher. Finally, for hazard rate computation and opportunity cost analysis, the methodology returns to a 20-60-20 time-based classification. This ensures that lifecycle phase definitions remain aligned with operational timelines, maintaining internal consistency across failure modes and supporting a coherent interpretation of results throughout the modelling framework.
For Liners and Chutes, where enough data points were available, these phases were carved out empirically, using the first 20 % of data to capture early, life failures, the middle 60 % for steady operation, and the last 20 % for end, of, life deterioration. Within each phase, Weibull distributions were fitted, allowing the distinct shapes and scales of the lifecycle to emerge. For Bearings, however, the story was different. With only four failures, any attempt at direct fitting would be statistically fragile. Here, the approach shifted to one of pragmatic assumption: calculate an overall MTBF from total hours and failure count, then assign phase, specific shapes (decreasing, flat, and increasing hazards) that reflected the engineering intuition of the bathtub curve. Scale parameters were then inferred to match these assumed shapes. Table 4 summarises the failure mode data.
Table 4Summary of failure mode data
Failure mode | No. of failures | Total operating hours | MTBF (hrs) | Data characteristics | Phase segmentation approach |
Bearings | 4 | 11,640 | 2,910 | Data-scarce, limited records | MTBF-based scale estimation; assumed for infant, random, wear-out phases |
Liners | 36 | 11,640 | ~323 | Moderate dataset, recurring wear failures | Empirical phase cut-offs (20 %- 60 %-20 %), Weibull fitting by phase |
Chutes | 90+ | 11,640 | ~129 | Data-rich, frequent operational disruptions | Empirical phase cut-offs (20 %- 60 %-20 %), Weibull fitting by phase |
Fig. 2 illustrates the classical bathtub curve, which serves as the conceptual foundation for lifecycle modelling in this study. The curve captures the three distinct phases of asset reliability: the infant mortality phase, where failures are driven by design flaws, installation errors, or early‐life weaknesses; the random failure phase, characterised by a relatively constant hazard rate where operational stresses dominate; and the wear‐out phase, where degradation mechanisms accelerate and failure likelihood rises sharply. This tripartite shape is widely recognised in reliability engineering as a simplified but powerful representation of how assets evolve over time. In the context of this study, the bathtub curve provides the structure for dividing failure data into lifecycle phases, allowing Weibull distributions to be fitted separately for each segment. This phase‐wise segmentation ensures that the subsequent hazard and cost modelling is sensitive to lifecycle dynamics rather than assuming uniform behaviour across the full operating life.
Fig. 2Bathtub curve [62]
![Bathtub curve [62]](https://static-01.extrica.com/articles/25932/25932-img2.jpg)
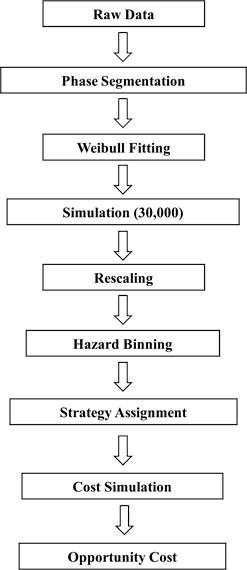
Fig. 3 illustrates the simulation workflow, outlining the sequential steps from raw data through hazard modelling to opportunity cost.
Fig. 3Simulation flowchart
Once the parameters were estimated, the next step was to bring them to life through simulation. A large synthetic dataset was generated, 30,000 simulated lifetimes per mode, carefully balanced across phases (30 % infant, 40 % random, 30 % wear-out). This ensured that the dynamics of each phase were richly represented, even when empirical data were sparse. Yet these simulations were not left floating in their raw form. To allow the three failure modes to speak the same temporal language, all simulated times were rescaled onto the shared horizon of 11,640 hours. This act of rescaling preserved the relative ordering of failures while creating a common frame of reference.
With failures mapped onto the unified timeline, the analysis next turned to the estimation of hazard. To quantify the time-dependent risk of failure, the study employed the Weibull hazard function, one of the most widely used models in reliability engineering due to its flexibility in representing different lifecycle behaviours. The general form of the hazard rate is expressed as: , where (shape parameter) governs the pattern of failure and (scale parameter) represents the characteristic life. Values of 1, indicate decreasing hazard rates typical of infant mortality, 1, corresponds to the constant hazard of the random failure phase, and 1captures the accelerating risk of wear-out. To reflect these behaviours, Weibull models were fitted separately for each lifecycle segment, using piecewise Weibull distributions, ensuring that hazard estimation aligned with the physics of failure rather than a uniform trend across the full life. Each simulated lifetime was then mapped back to its phase using the proportion of elapsed life, the first 20 % of the horizon for infant mortality, the middle 60 % for random failures, and the final 20 % for wear-out. Fig. 4 presents a representative view of piecewise Weibull failure phases, highlighting the infant mortality, random failure, and wear-out regions of the lifecycle.
Hazard rates were computed directly from the Weibull distribution for each failure mode and phase. To enable meaningful comparisons across components with varying risk magnitudes, these hazard rates were normalized to a [0.01, 1] scale within each lifecycle phase. This transformation facilitated consistent hazard binning while suppressing the dominance of extreme values from any single mode, thus preserving the relative risk dynamics necessary for unbiased cross-phase analysis. However, this normalization inherently removes absolute interpretability of the hazard values. To address this, the original unscaled hazard rates were retained in the framework to support any applications requiring absolute risk references. Following hazard binning, maintenance strategies were allocated using a balanced, randomized method, ensuring equal representation of Corrective (CM), Condition-Based (CBM), and Time-Based (TBM) maintenance within each bin. This approach prevented the introduction of bias through skewed policy distributions, enabling a robust comparison of strategy effectiveness across the full hazard spectrum.
Fig. 4Representative view of piecewise Weibull failure phases
The real innovation came with cost modelling. Instead of treating strategy costs as static, they were simulated with the same flexibility as failure times. The base cost values for the three maintenance strategies were anchored in both empirical data and literature evidence to ensure realism. For Corrective Maintenance (CM) and Time-Based Maintenance (TBM), cost inputs were taken directly from industry data records, reflecting observed averages for unplanned failure repair events and scheduled interventions respectively. In contrast, the base cost for Condition-Based Maintenance (CBM) was derived indirectly, recognising that its effectiveness depends on the detection efficiency of monitoring systems. Drawing on the work of [63], who reported an 80.2 % detection efficiency for CBM in industrial settings, the CBM cost was modelled as a weighted combination of TBM and CM costs. The underlying assumption is that when detection is successful (80.2 % of cases), CBM behaves economically like TBM, but when detection fails (19.8 % of cases), the system defaults to CM. This relationship was expressed as: CBM Cost = (0.802 × TBM) + (0.198 × CM).
Substituting the base values of TBM = $2100 and CM = $2500, the resulting estimate for CBM was: CBM Cost = (0.802 × 2100) + (0.198 × 2500) = $2179.2.
Using these values as anchors, subsequent Weibull-based cost simulations incorporated lifecycle variability by adjusting the dispersion (shape parameter) for each phase, while retaining these base costs as central reference points. This approach ensured that the economic evaluation was both grounded in operational reality and sensitive to the uncertainty inherent in maintenance outcomes.
This structure created the space to quantify opportunity cost. To evaluate the economic implications of maintenance strategy selection, this study introduced opportunity cost as the central decision indicator. Opportunity cost was defined as the additional cost incurred when the assigned strategy is not the most economical option. To formalize the concept of opportunity cost within this framework, the relevant variables are first defined. Let S = (CM, CBM, TBM) denote the set of available maintenance strategies, and let represent the expected cost associated with a given strategy , which is determined by the prevailing hazard rate, lifecycle phase, and underlying cost modelling assumptions. The cost of the strategy actually implemented for a specific observation or hazard bin is denoted as Cassigned, while Coptimal represents the minimum cost across all available strategies under the same conditions, corresponding to the economically most efficient option. Based on these definitions, the derivation proceeds in three steps. First, the optimal benchmark is established as Coptimal = , ensuring that the most cost-effective strategy under the given condition is identified. Second, the deviation from this benchmark is quantified as the opportunity cost, defined as the difference between the cost of the assigned strategy and the optimal strategy. Thus, the basic formulation emerges directly from comparing the assigned cost with the optimal benchmark: Opportunity Cost = Cassigned – Coptimal.
Finally, the interpretation of this formulation follows directly: if the assigned strategy coincides with the optimal (Cassigned = Coptimal), the opportunity cost is zero, signifying no economic penalty; whereas if the assigned strategy is more expensive than the optimal (Cassigned > Coptimal), the resulting positive difference reflects the economic loss, or regret, associated with a suboptimal choice. Thus, the opportunity cost expression arises naturally from the comparative evaluation of the assigned strategy against the optimal benchmark, providing a rigorous basis for assessing the economic implications of maintenance strategy decisions.
To enable comparisons across different modes, phases, and hazard bins, the metric was further normalized into a percentage form, reflecting the relative penalty of choosing suboptimal strategies: % Opportunity Cost =100 × (Cassigned – Coptimal) / Coptimal.
This formulation highlights not only which strategy is cheapest on average, but also the economic regret associated with not selecting the optimal alternative. A value of zero indicates that the chosen strategy coincided with the most cost-effective option, while higher percentages quantify the penalty of misalignment in relative terms. By using this regret-based measure, the framework reframes maintenance evaluation from static cost comparison to dynamic benchmarking, providing decision-makers with a transparent and intuitive tool for assessing the consequences of maintenance policy choices across the asset lifecycle.
The resulting methodology was thus more than a procedural pipeline; it was a story of engineering judgment meeting statistical rigor. By respecting raw data, segmenting lifecycles, simulating at scale, normalizing hazards, balancing strategies, and embedding costs in the same probabilistic framework, the analysis offered a nuanced view of maintenance decisions. The opportunity cost lens reframed the question: not simply which strategy is cheapest on average, but how much one might regret the choice when compared to the best available alternative at any point in the asset’s life.
5. Results
The application of this methodology revealed how the three selected failure modes behave across their lifecycles and, more importantly, how different maintenance strategies translate into economic performance when evaluated through the lens of opportunity cost. By simulating lifetimes and rescaling them onto a shared horizon, the characteristic shape of the bathtub curve became visible for Bearings, Liners, and Chutes, albeit with distinct nuances in each case. The first step in interpreting the results was to test whether the observed patterns aligned with the theoretical expectations derived earlier. Three hypotheses were proposed: that Corrective Maintenance (CM) would dominate in low-hazard conditions (H1), that Condition-Based Maintenance (CBM) would minimize costs in moderate hazard regions (H2), and that Time-Based Maintenance (TBM) would outperform in high-hazard wear-out phases (H3).
The results provided partial but compelling support for the three hypotheses. In the lowest hazard bins, CM did not consistently dominate across all modes. While theory predicted CM would be cheapest in early-life conditions, the simulations showed that for Chutes and Liners, TBM already outperformed CM even in relatively low hazard regions, owing to their wear-driven and steady degradation behaviours. Only in selected regions of the Bearings dataset, where failures were sparse and uncertainty high, did CM appear less penalising, which reflects both the small data base and the multi-modal nature of bearing failures. The aggregated results broadly reflected the expectations set out in the a priori theory: corrective strategies were least penalising only in low-risk conditions, condition-based approaches offered benefits in parts of the mid-life phase, and time-based interventions became essential in wear-out regimes. However, the strength and clarity of these dominance patterns varied across the three failure modes. In some cases, the theoretical boundaries between strategies were sharply visible; in others, data scarcity or multi-modal behaviour introduced greater uncertainty. To understand these differences more clearly, the mode-specific results for Chutes, Liners, and Bearings are presented below.
Fig. 5 presents the relationship between mean opportunity cost and normalised hazard rate bins for the chute, offering a comparative assessment of CM, CBM, and TBM across the infant, random, and wear-out phases. For the chute failure mode, the results reveal a relatively stable and predictable profile, with opportunity cost values remaining within a narrow band across the hazard spectrum. Corrective maintenance consistently exhibits the highest regret, reflecting the economic penalty of unplanned downtime in a failure mode characterised by steady degradation. Time-based maintenance, by contrast, dominates economic performance across almost all hazard bins, trending toward near-zero regret in the lower hazard ranges. This outcome is consistent with the moderate shape factor estimated for chute deterioration, which aligns with gradual wear mechanisms that are well matched to scheduled replacement. Condition-based maintenance demonstrates intermediate performance, providing some protection against failure but never achieving parity with TBM due to the added costs of inspection and monitoring. These findings highlight that in components with stable degradation profiles, proactive scheduling of interventions is both technically and economically superior, while reliance on reactive approaches imposes a persistent financial burden.
Fig. 6 presents the relationship between mean opportunity cost and normalised hazard rate bins for the liners, offering a comparative assessment of CM, CBM, and TBM across the infant, random, and wear-out phases. The liners, however, exhibit a much more pronounced and volatile opportunity cost trajectory, underlining their sensitivity to wear, driven degradation processes with a high Weibull shape parameter. In the higher hazard bins, the regret associated with corrective and condition-based maintenance escalates sharply, often approaching or exceeding catastrophic levels close to 100 %. This steep rise indicates that once liners enter the wear-out phase, the window for effective intervention narrows considerably, making reactive strategies economically untenable. The dominance of time-based maintenance is evident here, as it steadily reduces opportunity cost across the hazard spectrum, demonstrating its ability to prevent catastrophic failures through scheduled replacements. Condition based maintenance offers limited improvement in lower hazard bins but fails to provide a viable alternative once the hazard rate accelerates, as the cost of continuous monitoring cannot offset the rapid escalation of wear, related failures. The liners plot therefore provides a clear empirical validation of theoretical expectations: in systems governed by strong wear-out dynamics, proactive scheduling is not only preferable but essential to avoiding disproportionate economic regret.
Fig. 5Chute: mean percentage opportunity cost vs normalised hazard rate bin
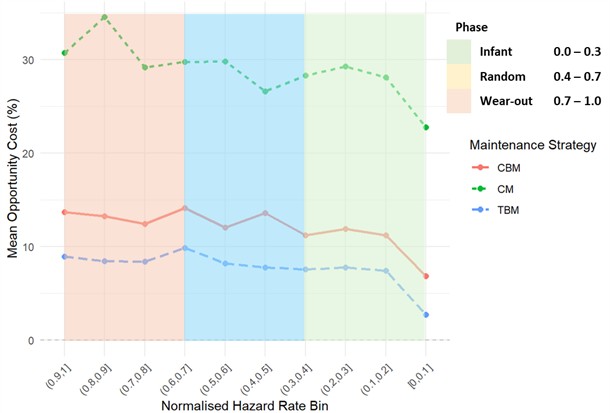
Fig. 6Liners: mean percentage opportunity cost vs normalised hazard rate bin
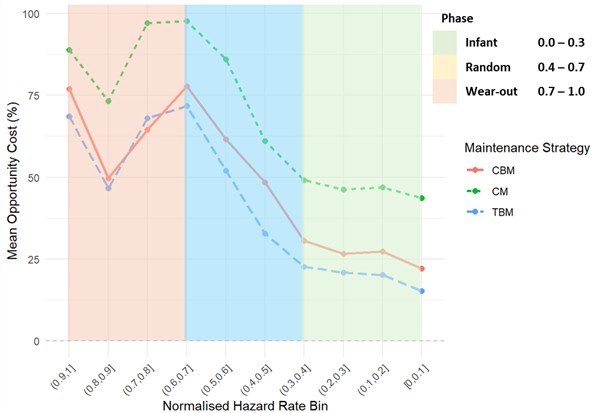
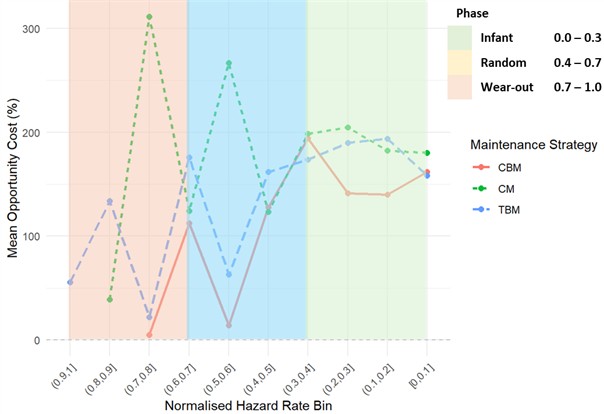
Fig. 7 presents the relationship between mean opportunity cost and normalised hazard rate bins for the chute, offering a comparative assessment of CM, CBM, and TBM across the infant, random, and wear-out phases. The bearings present the most irregular and complex opportunity cost profile, with pronounced volatility across the hazard bins. Spikes in corrective maintenance regret exceed 300 % in certain regions, reflecting both the high costs of unplanned bearing failures and the statistical instability introduced by sparse failure data. Unlike the chutes and liners, bearing failures are inherently multi, modal, spanning infant mortality, random shocks, and wear - out phenomena. This multi, phase behaviour creates oscillations in the hazard function, which are translated into fluctuating regret profiles across maintenance strategies. Economically, the implications are twofold: first, corrective maintenance consistently emerges as the least viable strategy, with regret levels so high that they can compromise operational viability. Second, while condition-based and time-based maintenance alternate in relative advantage across hazard bins, neither provides a consistently dominant strategy. CBM demonstrates superior performance in certain early hazard ranges, where the detection of incipient defects offers tangible savings, but its effectiveness diminishes in mid, life phases where inspection costs accumulate. Conversely, TBM provides more stability in the mid, to, low hazard regions, though it is not immune to variability. The irregularity observed in the bearings case underscores the need to explicitly account for uncertainty in both hazard rate estimation and economic benchmarking. Deterministic interpretations alone may yield misleading recommendations, and adaptive or probabilistic decision rules are necessary to provide a more robust framework for strategy selection in such failure modes.
Fig. 7Bearings: mean percentage opportunity cost vs normalised hazard rate bin
Taken together, these results both validate the theoretical hypotheses and extend them with richer empirical insights. Chutes exemplify the value of TBM in systems with steady degradation, Liners demonstrate the catastrophic risks of reactive practices in wear-out regimes, and Bearings highlight the uncertainty inherent in sparse or multi-modal data. The framework thus confirms the phase-wise dominance patterns predicted in theory (H1-H3) while also showing that the strength, clarity, and stability of these transitions are failure-mode dependent. To reinforce the validity of these results, the analysis incorporates 95 % confidence intervals around the mean estimates. This approach moves beyond reporting central tendencies alone and provides a more rigorous statistical basis for interpreting the comparative performance of maintenance strategies. By explicitly quantifying the uncertainty associated with each estimate, the confidence intervals enable a clearer distinction between stable trends and outcomes that are more sensitive to data variability. This, in turn, ensures that the assessment of strategy effectiveness is not only based on average behaviour but also on the reliability and robustness of those averages across different phases of the asset lifecycle.
Fig. 8 presents the mean percentage opportunity cost for the Chute failure mode across normalised hazard rate bins, with error bars showing the 95% confidence intervals. The results highlight three important trends. First, corrective maintenance (CM) exhibits both the highest mean opportunity costs and the widest confidence intervals, especially in the higher hazard bins, indicating not only inferior economic performance but also greater uncertainty in outcomes. Second, condition-based maintenance (CBM) maintains a mid-level cost profile with relatively narrower confidence intervals, suggesting moderate stability across lifecycle phases. Finally, time-based maintenance (TBM) consistently produces the lowest opportunity costs, with the narrowest confidence intervals, reflecting a more predictable and robust economic outcome. The contrast in interval width across strategies underscores the reliability of TBM and CBM, while also showing that CM introduces significant variability and decision risk, particularly as the asset enters wear-out phases.
Fig. 8Chute: mean percentage opportunity cost vs normalised hazard rate bin with 95 % confidence intervals
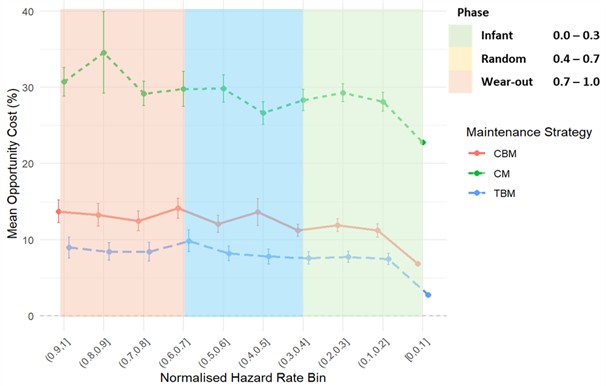
Fig. 9 shows the mean percentage opportunity cost for the Liners failure mode across normalised hazard rate bins, with error bars representing 95 % confidence intervals. The results indicate that corrective maintenance (CM) consistently incurs the highest opportunity cost, particularly in the wear-out phase, and also demonstrates greater variability in outcomes. Condition-based maintenance (CBM) follows a mid-range trend but converges closely with time-based maintenance (TBM) in certain hazard bins, especially during the transition from wear-out to random phases. TBM exhibits the lowest and most stable costs across the majority of bins, with narrow confidence intervals highlighting its reliability. Overall, the contrasting widths of the confidence intervals reinforce that CM is economically riskier and less predictable, whereas TBM and CBM provide more consistent cost performance throughout the asset lifecycle.
Fig. 10 illustrates the mean percentage opportunity cost for the Bearings failure mode across normalised hazard rate bins, with 95 % confidence intervals shown as error bars. Compared to Chute and Liners, the Bearings results exhibit far greater variability, with wide confidence intervals and sharp fluctuations across bins. This instability reflects the sparse and uncertain failure data available for bearings, amplifying the statistical noise and reducing the reliability of strategy comparisons. Corrective maintenance (CM) shows extreme spikes in cost and uncertainty, reinforcing its unsuitability under high-risk conditions. Condition-based maintenance (CBM) and time-based maintenance (TBM) display comparatively lower costs in certain bins, but their relative advantages are less consistent due to the volatility of the estimates. Overall, the plot highlights how data scarcity for bearings introduces significant uncertainty, demonstrating the need for stronger data inputs or longer monitoring horizons before making robust maintenance strategy decisions.
Fig. 9Liners: mean percentage opportunity cost vs normalised hazard rate bin with 95 % confidence intervals
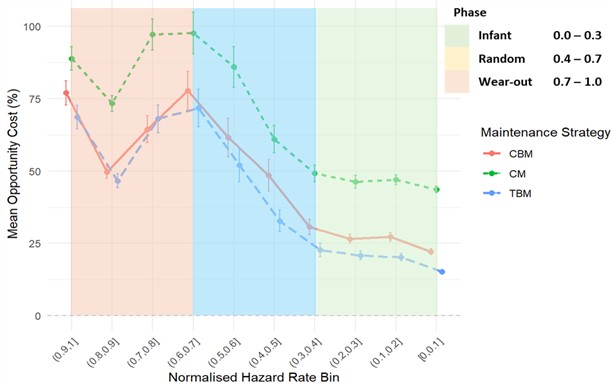
Fig. 10Bearings: mean percentage opportunity cost vs normalised hazard rate bin with 95 % confidence intervals
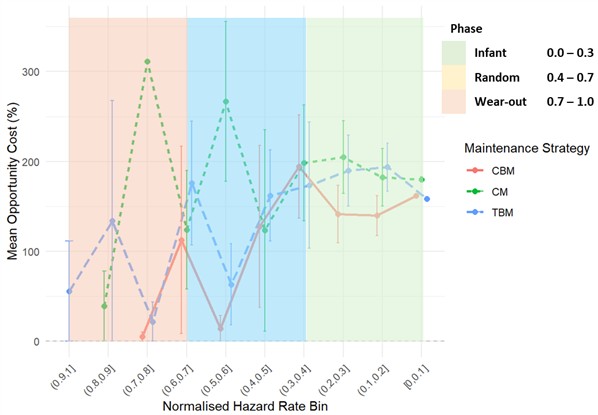
The confidence interval analysis provides an important layer of depth to the results by situating the mean opportunity cost estimates within the broader range of possible outcomes. Rather than relying solely on point estimates of strategy performance, the use of 95 % confidence intervals ensures that the conclusions account for the inherent uncertainty present in failure data and simulation outputs. This statistical framing is essential for maintenance decision-making, where risk and reliability are as critical as cost minimisation. By explicitly quantifying the variability surrounding each mean estimate, the analysis allows decision-makers to distinguish between strategies that are both cost-effective and reliable, and those whose performance may appear favourable on average but is undermined by high volatility.
From this perspective, the results continue to reinforce the theoretical hypotheses (H1-H3) while also extending them with new insights. Hypothesis 1 (H1), which predicted the dominance of corrective maintenance (CM) under low-hazard conditions, is supported only within narrow and unstable intervals, as the wide confidence bands associated with CM reveal significant unpredictability even when failures are relatively infrequent. Hypothesis 2 (H2), which anticipated the superiority of condition-based maintenance (CBM) in moderate hazard regimes, is confirmed by the narrower confidence intervals surrounding CBM compared with CM. This suggests that monitoring and planned interventions not only reduce average costs but also deliver greater stability across simulations. Finally, Hypothesis 3 (H3), which proposed that time-based maintenance (TBM) would dominate in high-hazard or wear-out regimes, is validated in the clearest and most consistent way. The TBM results show both the lowest mean costs and the narrowest confidence intervals, underscoring its role as the most predictable and resilient strategy in phases of accelerated degradation.
Importantly, the confidence interval analysis also demonstrates that the sharpness and clarity of these dominance patterns vary across failure modes. For Chutes, the transition is strong and stable, with TBM emerging as the clear and reliable choice. For Liners, CM performs worst not only in mean cost but also in variability, amplifying the risks of a reactive approach in wear-out regimes. For Bearings, however, the wide intervals and fluctuating means reveal the challenge of working with sparse or multi-modal data, where strategy comparisons become less definitive. This highlights a key contribution of the framework: rather than assuming that theoretical dominance patterns will manifest uniformly, it acknowledges that real-world decision-making is shaped by data quality, sample variability, and the reliability behaviour of each component.
Taken together, these findings confirm that hazard-based modelling integrated with opportunity cost offers more than theoretical validation – it provides a robust decision-support framework that explicitly incorporates uncertainty. By embedding confidence intervals into the analysis, the framework allows practitioners to evaluate not only which strategy appears optimal on average but also how reliably that strategy can be expected to perform under uncertain conditions. This dual focus on mean performance and variability strengthens the case for data-driven maintenance planning, as it aligns economic optimisation with risk awareness. Ultimately, the results advance the theoretical hypotheses (H1-H3) by showing that their practical validity depends not just on lifecycle phase, but also on the statistical confidence with which strategy performance can be distinguished, an aspect that is crucial for both academic understanding and industry application.
6. Significance of the study
The present study builds upon an earlier multi-stage risk assessment framework [61] by extending it from a diagnostic tool into a decision-oriented methodology. While the prior framework enabled the identification and prioritisation of critical failure modes based on likelihood and consequence, it did not explicitly address how maintenance strategies should be selected as failure behaviour evolves over the asset lifecycle. The significance of this extension lies in shifting the focus from ‘where risk exists’ to ‘how decisions should adapt in response to that risk over time’, thereby closing a key gap between risk assessment and actionable maintenance planning. The significance of this study lies in its ability to move maintenance decision-making from static, rule-based evaluation to a dynamic, lifecycle-aware framework that explicitly links reliability behaviour with economic consequences.
The proposed framework integrates hazard rate modelling with probabilistic cost analysis, allowing maintenance strategies to be evaluated as a function of time-varying risk rather than static assumptions. This is important because real-world assets rarely operate under constant failure conditions; instead, their risk profiles evolve across lifecycle phases. By embedding this dynamic behaviour into the evaluation process, the framework provides a more realistic basis for comparing strategies, particularly in environments where failure behaviour is non-linear and phase dependent.
In comparison to existing hazard-based maintenance approaches, the proposed framework introduces several important distinctions. Proportional Hazards Model (PHM)-based methods typically rely on external covariates to model failure behaviour, making them dependent on the availability and quality of condition monitoring data [44, 50]. In contrast, the present study models hazard rate evolution directly using Weibull-based simulation, allowing the framework to remain applicable in environments where such data may be limited. Similarly, Generalised Renewal Process (GRP) models provide detailed representations of imperfect maintenance effects but often involve significant mathematical complexity and parameter estimation challenges [46]. The current approach adopts a simplified and scalable structure, prioritising interpretability and integration with economic evaluation over detailed restoration modelling. From an economic perspective, existing maintenance optimisation studies commonly rely on deterministic or average cost assumptions, which may not fully capture variability across lifecycle phases. The present framework differs by incorporating probabilistic cost modelling linked directly to hazard behaviour, enabling cost variability to be explicitly represented. Furthermore, while prior studies evaluate strategies based on expected cost or cost–benefit comparisons [48, 49], they do not explicitly quantify the economic consequence of suboptimal decisions. The introduction of opportunity cost as a regret-based decision metric provides a distinct and more informative basis for evaluating maintenance strategies under uncertainty.
A further strength of the framework lies in its ability to operate across heterogeneous data environments. In practice, maintenance datasets are rarely uniform, some components are well-instrumented, while others suffer from sparse or incomplete records. By combining empirical estimation with assumption-based modelling, the methodology remains applicable across this spectrum. The use of hazard normalisation and a common lifecycle horizon is particularly significant here, as it ensures that differences in data richness do not prevent meaningful comparison. This enables decision-making to remain consistent even when data quality varies across assets.
The structured evaluation of strategies within hazard-based bins introduces a state-dependent perspective to maintenance decision-making. Rather than relying on global averages, which can obscure important lifecycle-specific behaviour, the framework allows strategies to be assessed within defined risk conditions. This matters because the effectiveness of a maintenance strategy is inherently context-dependent; a strategy that performs well under low hazard may become economically inefficient as risk intensifies. By localising the analysis, the framework makes these transitions visible and actionable.
From an economic perspective, the introduction of opportunity cost as a decision indicator provides a critical shift in how strategy performance is interpreted. Instead of focusing solely on identifying the lowest-cost option, the framework quantifies the consequence of selecting a suboptimal strategy. This is particularly relevant in practice, where uncertainty and incomplete information often make perfect decisions unlikely. By expressing performance in terms of economic regret, the framework offers a more intuitive and decision-relevant metric that aligns closely with how maintenance choices are evaluated in real operational settings.
In addition, the use of probabilistic cost modelling enhances the realism of the analysis by capturing variability in maintenance outcomes across lifecycle phases. Conventional approaches often rely on deterministic cost values, which can mask the uncertainty inherent in real operations. By modelling costs as distributions, the framework acknowledges that economic outcomes are not fixed but influenced by lifecycle stage, failure behaviour, and operational variability. This provides a more robust basis for comparing strategies under uncertainty.
Overall, the framework advances maintenance decision-making by integrating reliability behaviour, economic evaluation, and uncertainty into a unified approach. Its importance lies not only in methodological integration, but in its ability to translate complex reliability dynamics into economically meaningful insights. In doing so, it provides a practical decision-support tool that enables asset managers to align maintenance strategies with both lifecycle risk and economic impact, strengthening the link between engineering analysis and operational decision-making.
7. Discussion
The results of this study provide a deeper and more nuanced understanding of maintenance strategy performance than was possible in the earlier multi-stage risk assessment [61]. By embedding hazard-based lifecycle modelling within a probabilistic cost framework, the analysis revealed not only how Bearings, Liners, and Chutes evolve across their operational lives, but also how the choice of maintenance strategy interacts with hazard intensity to create measurable economic consequences. This represents a significant methodological evolution: the earlier framework mapped “where risks lie”, while the present study demonstrates “how best to respond to them” in economic terms. Such a shift reframes maintenance from a largely diagnostic exercise into a prescriptive, decision-oriented process grounded in risk-cost trade-offs.
A key insight emerging from the analysis is that no single maintenance strategy is universally optimal across all conditions. This finding reinforces long-standing engineering intuition: strategies must be tailored to lifecycle stage and failure behaviour. What this study adds is an explicit quantification of the economic penalty of being wrong, expressed through opportunity cost. For example, the clear rise in regret associated with Corrective Maintenance in wear-out bins illustrates the escalating risk of persisting with reactive practices as assets age. Conversely, the narrowing of opportunity cost differences in low-hazard zones suggests that early-life or low-risk conditions afford greater flexibility, where even suboptimal choices impose minimal penalties. This reframing of maintenance decision-making in terms of regret rather than absolute cost provides a defensible and intuitive benchmark for managers navigating uncertainty, bridging the gap between engineering analysis and economic accountability.
The cross-mode comparisons further highlight the importance of normalization and binning as analytical techniques. By rescaling hazard values within each mode and phase, the framework created a level playing field that enabled Bearings, Liners, and Chutes, despite their very different data densities, to be compared directly. This revealed cross-cutting patterns, such as the consistent superiority of CBM in wear-out phases and the dominance of TBM in more predictable regimes. Without normalization, these patterns would likely have been obscured by the sheer weight of chute failures, which could easily overwhelm analyses with their volume alone. This design choice therefore strengthens the generalizability of the findings and illustrates how heterogeneous datasets can yield actionable insights when carefully harmonized.
Equally important is the demonstration of how data scarcity and data richness can be accommodated within one unified framework. The Bearings case- based on only a handful of recorded failures, showed that meaningful hazard and cost profiles can still be constructed when assumptions are made transparently and linked back to engineering judgment. This is critical for industries where data are fragmented or incomplete, as it demonstrates that structured modelling can still inform decision-making without requiring exhaustive datasets. In contrast, Liners and Chutes, with richer datasets, allowed for finer-grained Weibull fitting and more stable estimates of opportunity cost. Liners in particular highlighted the transitional nature of wear-related failures, showing how CBM excels when hazard levels begin to rise but variability remains high, before TBM becomes more cost-effective as hazard stabilises at higher levels. Chutes, supported by extensive records, generated statistically stable hazard and cost profiles, making them an ideal demonstration of the framework’s ability to yield robust, phase-wise strategy recommendations. Together, these cases highlight the balance between assumption-driven modelling and data-driven inference, reflecting the reality that maintenance contexts rarely provide uniformly rich datasets across all components.
Another important contribution lies in how the opportunity cost framing sharpens decision-making under uncertainty. In practice, maintenance planning often relies on expected value comparisons that mask the risks of error. By explicitly quantifying regret, this study makes visible the asymmetry of economic consequences: being wrong in low-hazard phases is relatively benign, but being wrong in high-hazard phases is disproportionately costly. This insight encourages managers to take a dynamic view of strategy selection, aligning decision effort with lifecycle risk intensity. It also underscores the danger of static, one-size-fits-all policies, particularly for assets with accelerating hazard profiles where reactive strategies carry escalating costs.
From a managerial standpoint, the implications of this research are significant. The framework equips asset managers with a decision-support tool that is both rigorous and accessible. Its ability to harmonize heterogeneous datasets means it can be deployed across a wide range of components without requiring uniform data availability. Its translation of hazard modelling into economic regret provides a language that resonates with both technical and financial stakeholders, enabling more transparent communication between engineers, planners, and executives. For example, an asset manager can now articulate not just “which” strategy is cheaper, but “what the cost of being wrong would be”. This reframing makes investment decisions, such as whether to adopt CBM technology or continue with TBM schedules, more defensible and evidence based.
Moreover, the framework offers flexibility in application. It can be used retrospectively to evaluate existing policies, prospectively to test alternative strategies, or strategically to prioritise investments in monitoring technologies. For instance, if the analysis reveals that CBM consistently reduces regret in the wear-out phase of liners, this can be used to justify investment in vibration sensors or inspection protocols targeted at that stage. Similarly, if TBM emerges as consistently dominant in high-volume failure modes like chutes, scheduling optimisation can focus on aligning service intervals with hazard trajectories to maximise efficiency.
At the same time, the study acknowledges its limitations. The lifecycle phase cut-offs at 20 % and 80 % of total life, while practical, are heuristic assumptions; alternative thresholds or data-driven change-point detection could refine phase segmentation. The use of Weibull distributions, although standard in reliability engineering, may not fully capture behaviours where failures are multi-modal or where costs follow heavy-tailed distributions. Normalization, while essential for comparability, reduces interpretability of absolute hazard values, restricting conclusions to relative rather than absolute risk intensity. In data-scarce contexts such as Bearings, sensitivity to parameterisation means results should be treated with caution, with confidence intervals explicitly communicated. A key limitation of this analysis lies in the reliance on estimated cost inputs for each maintenance strategy. While the modelling framework assigns representative values to corrective, condition-based, and time-based maintenance, these estimates inevitably simplify the complexity of real-world cost structures. In practice, actual costs can vary considerably depending on factors such as site-specific labour rates, production loss valuations, equipment accessibility, and the effectiveness of monitoring technologies. Moreover, the simulation assumes static cost parameters across lifecycle phases, whereas in reality these values may evolve dynamically as assets age, technologies improve, or operational contexts change. As a result, while the presented results provide a robust comparative framework, they should be interpreted as indicative rather than absolute, with the recognition that more granular cost data could enhance both accuracy and industry relevance. In addition, the equal distribution of maintenance strategies across hazard bins does not reflect how strategies are typically deployed in operational environments. In practice, the allocation of maintenance strategies often varies with operational context, risk tolerance, and resource availability, rather than following a uniform pattern across risk levels. However, in this model, equal assignment was adopted to avoid introducing bias in the cost-performance comparison. By ensuring that each strategy was represented across all risk levels, the analysis could isolate performance differences attributable to the strategies themselves, rather than to uneven exposure. While this design improves experimental control, it limits direct reflection of real-world strategy distribution. The presented results should therefore be viewed as foundational, with future research encouraged to incorporate realistic deployment patterns.
These limitations provide fertile ground for future work. Extending the framework to incorporate compound failure interactions or subsystem dependencies would provide a more realistic representation of industrial assets. Integrating digital twins and real-time sensor data offers the potential to transform opportunity cost into a dynamic indicator, continuously updating as hazard estimates evolve with operational data. Furthermore, calibrating cost distributions using industry-specific maintenance logs would enhance the realism and adoption of the framework in practice. There is also scope to test the framework across sectors, such as energy, transportation, or manufacturing, to assess its generalisability beyond mining. Finally, coupling the approach with multi-objective optimisation could allow trade-offs between cost, safety, and availability to be modelled explicitly, further strengthening its managerial relevance.
In summary, this study advances maintenance decision-making by moving beyond the diagnostic role of the multi-stage risk assessment to provide a prescriptive, economically grounded decision-support framework. By introducing opportunity cost as a unifying indicator, harmonizing heterogeneous datasets through normalization, and demonstrating robustness across both sparse and rich data environments, the study builds a novel bridge between theoretical reliability modelling and the practical realities of industrial maintenance. The framework positions itself not only as an academic contribution but also as a decision compass for asset managers, guiding strategy selection across the lifecycle by balancing cost, risk, and regret. In doing so, it marks an important step toward transparent, data-informed, and economically defensible maintenance planning in complex industrial environments.
8. Conclusions
This study set out to extend the authors earlier work [61] on multi-stage risk assessment framework by moving beyond the identification of critical failure modes to examine how maintenance strategies perform across the lifecycle of those failures. The earlier multi - stage framework provided an essential diagnostic foundation, showing which components contributed most to downtime, cost, and overall system vulnerability. However, it left unanswered the equally important question of how maintenance interventions should be aligned with the evolving risk profile of those components. In other words, it identified where risks lie, but not how best to respond. Addressing this gap required the integration of reliability modelling with an economic lens, shifting the focus from criticality alone to decision-making under uncertainty.
The methodology presented in this study represents a conceptual and technical evolution of that earlier work. By embedding Weibull-based hazard modelling within a probabilistic cost framework, the analysis moves from risk description to strategy prescription. The novelty lies in evaluating maintenance options not purely on expected cost, but on the opportunity cost, the economic penalty incurred when the selected strategy is not the optimal one. This subtle but powerful reframing makes explicit the consequences of poor decision-making and provides a transparent, quantitative justification for shifting strategies as assets progress through their lifecycle.
The analysis of three representative failure modes, Bearings, Liners, and Chutes provided a compelling demonstration of the framework’s flexibility and adaptability. Each mode represented a distinct data environment, thereby testing the robustness of the methodology under varying empirical conditions. The Bearings case illustrated the reality of data scarcity, where only a handful of failures were available for modelling. Instead of being discarded as unusable, the data were embedded within a Weibull framework supported by transparent assumptions and engineering judgment. This showed that meaningful hazard and cost trajectories can still be constructed even under severe data limitations, provided that the uncertainties are acknowledged and communicated. Liners, with a moderate dataset, enabled more refined phase-wise fitting, capturing the dynamics of failures associated with progressive wear. This case demonstrated the capacity of the model to detect transitions across lifecycle phases and to evaluate when preventive strategies should replace reactive ones. Chutes, with extensive records, offered a contrasting scenario where statistical stability could be achieved. The large dataset allowed for robust hazard estimation and stable cost simulations, providing confidence in the results. Taken together, the three cases demonstrated that the methodology can accommodate heterogeneity in data richness without sacrificing comparability, an essential feature for real-world industrial applications where datasets are rarely uniform across components.
One of the most important findings was that no single maintenance strategy emerged as universally optimal. This reinforces long-standing engineering intuition but elevates it through quantification. Corrective Maintenance (CM), while sometimes viable in early phases where hazard levels remain low, consistently produced significant economic regret in the wear-out region. The reliance on CM under high hazard conditions for Bearings vividly illustrated how reactive strategies expose organisations to escalating and unnecessary costs. Time-Based Maintenance (TBM), by contrast, proved highly effective for Chutes, reflecting their predictable hazard trajectory and the benefits of scheduled interventions. Liners revealed a more complex picture, where CBM excelled during the wear-out stage by addressing emerging risks proactively, while TBM became the preferred choice in later phases as hazard levels rose sharply. These patterns underscore the study’s central insight: strategy effectiveness is highly context- and phase-dependent, and the cost of being wrong grows disproportionately as assets age.
The introduction of opportunity cost as a unifying decision indicator is arguably the most novel contribution of this study. Traditional approaches to maintenance optimisation often stop at cost minimisation, reporting the lowest expected cost as the “best” strategy. Yet in practice, decision-makers must weigh not only the average cost but also the consequences of error. Opportunity cost reframes the decision space by quantifying the regret associated with choosing an inferior option. This allows managers to evaluate trade-offs in a language that is both intuitive and defensible. Instead of abstract comparisons of hazard or mean downtime, decision-makers can ask: “If we are wrong, what is the economic cost to us?” This shift better reflects the realities of industrial practice, where uncertainty is pervasive and where the economic consequences of error often drive managerial concern.
Beyond methodological innovation, the study carries several practical implications. For asset managers and maintenance planners, the framework provides a structured decision compass that can be integrated into routine evaluations of maintenance strategy. Its ability to accommodate both data-sparse and data-rich environments makes it versatile across industrial settings. The quantification of economic regret provides a communication tool for bridging engineering analysis with executive decision-making, translating technical risk into economic terms that align with budgetary and production priorities. The framework can be used not only for retrospective evaluation of existing policies but also for testing the implications of adopting alternative strategies or for justifying investments in condition monitoring technologies. For example, if opportunity cost analysis reveals that CBM consistently reduces regret in wear-out phases, this can be used to make a defensible case for investing in sensor technology and predictive analytics.
At the same time, the study is careful to acknowledge its limitations. The segmentation of lifecycle phases at 20 % and 80 % of total life, while commonly used, is ultimately a heuristic. Alternative cut-off points or data-driven change-point detection methods may provide more accurate phase delineations. Similarly, the reliance on Weibull distributions, while standard in reliability engineering, does not capture all possible dynamics, particularly in contexts where failure behaviour is multi-modal or where costs exhibit heavy-tailed distributions. Normalisation and binning, while enabling comparability across heterogeneous datasets, inevitably reduce the interpretability of absolute hazard values, meaning results must be interpreted as relative indicators rather than direct measures of risk. Finally, while simulation stabilised the estimates, sensitivity to parameterisation remains, particularly in the Bearings case where assumptions substituted for empirical richness.
These limitations suggest several avenues for future research. First, integrating alternative statistical models, including mixture distributions or non-parametric approaches, could better capture complex or compound failure behaviours. Second, embedding the framework within digital twin architectures would enable continuous updating of hazard and cost profiles using real-time sensor data, transforming opportunity cost from a static to a dynamic decision indicator. Third, expanding calibration of cost distributions using site-specific maintenance logs would enhance realism and strengthen adoption by industry stakeholders. Fourth, applying the framework to multi-component systems with interdependencies, rather than treating failure modes in isolation, could provide a more holistic view of system-level maintenance optimisation. Finally, cross-industry applications, beyond the mining context, would help to generalise the methodology and test its scalability in sectors such as manufacturing, energy, or transportation.
In summary, this study represents both a methodological and conceptual evolution of the multi-stage risk assessment framework. By embedding hazard modelling into an opportunity-cost framework, it provides a novel and practical decision support tool that aligns engineering analysis with economic accountability. The contribution lies not only in modelling failures and costs but in reframing maintenance decisions as choices that carry measurable regret. This reframing empowers decision-makers to move from reactive intuition to proactive, data-informed, and economically defensible strategies. The broader implication is a step toward more transparent and rationalised maintenance planning in complex industrial environments, where the balance between cost, risk, and performance remains a central challenge. Ultimately, this work bridges the gap between theory and practice, offering both an academic contribution to the reliability literature and a practical compass for asset managers navigating uncertainty across the asset lifecycle.
References
-
A. Gaikwad, “Advanced failure analysis techniques for field-failed units in industrial systems,” SSRN Electronic Journal, 2025, https://doi.org/10.2139/ssrn.5074912
-
S. More, R. Tuladhar, D. Grainger, and W. Milne, “Maintenance decision-making and its relevance in engineering asset management,” Maintenance, Reliability and Condition Monitoring, Vol. 4, No. 1, pp. 1–17, Jun. 2024, https://doi.org/10.21595/marc.2024.23687
-
G. Waeyenbergh and L. Pintelon, “A framework for maintenance concept development,” International Journal of Production Economics, Vol. 77, No. 3, pp. 299–313, Jun. 2002, https://doi.org/10.1016/s0925-5273(01)00156-6
-
A. Sharma, G. S. Yadava, and S. G. Deshmukh, “A literature review and future perspectives on maintenance optimization,” Journal of Quality in Maintenance Engineering, Vol. 17, No. 1, pp. 5–25, Mar. 2011, https://doi.org/10.1108/13552511111116222
-
A. Crespo Márquez, P. Moreu de León, J. Gómez Fernández, C. Parra Márquez, and M. López Campos, “The maintenance management framework: A practical view to maintenance management,” Journal of Quality in Maintenance Engineering, Vol. 15, No. 2, pp. 167–178, 2029.
-
M. Rausand and K. Øien, “The basic concepts of failure analysis,” Reliability Engineering and System Safety, Vol. 53, No. 1, pp. 73–83, 1996, https://doi.org/10.1016/0951-8320(96)00010-5
-
M. Edimu, C. T. Gaunt, and R. Herman, “Using probability distribution functions in reliability analyses,” Electric Power Systems Research, Vol. 81, No. 4, pp. 915–921, Apr. 2011, https://doi.org/10.1016/j.epsr.2010.11.022
-
H. Haroonabadi and M.-R. Haghifam, “Generation reliability evaluation in power markets using Monte Carlo simulation and neural networks,” in 15th International Conference on Intelligent System Applications to Power Systems, pp. 1–6, Nov. 2009, https://doi.org/10.1109/isap.2009.5352864
-
Y. M. Ko and E. Byon, “Reliability evaluation of large-scale systems with identical units,” IEEE Transactions on Reliability, Vol. 64, No. 1, pp. 420–434, Mar. 2015, https://doi.org/10.1109/tr.2014.2368895
-
J. Jones and J. Hayes, “Estimation of system reliability using a "non-constant failure rate" model,” IEEE Transactions on Reliability, Vol. 50, No. 3, pp. 286–288, 2001, https://doi.org/10.1109/24.974125
-
L. Hao, L. Bian, N. Gebraeel, and J. Shi, “Residual life prediction of multistage manufacturing processes with interaction between tool wear and product quality degradation,” IEEE Transactions on Automation Science and Engineering, Vol. 14, No. 2, pp. 1211–1224, Apr. 2017, https://doi.org/10.1109/tase.2015.2513208
-
L.-I. Tong, K. S. Chen, and H. T. Chen, “Statistical testing for assessing the performance of lifetime index of electronic components with exponential distribution,” International Journal of Quality and Reliability Management, Vol. 19, No. 7, pp. 812–824, 2002, https://doi.org/10.1108/02656710210434757
-
J. M. Barraza-Contreras, M. R. Piña-Monarrez, and A. Molina, “Fatigue-life prediction of mechanical element by using the Weibull distribution,” Applied Sciences, Vol. 10, No. 18, p. 6384, Sep. 2020, https://doi.org/10.3390/app10186384
-
D. Huang, “A sampling method of sequential tests with sample size limit under poisson distribution,” in IEEE International Conference on Electronics, Energy Systems and Power Engineering (EESPE), pp. 492–496, Mar. 2025, https://doi.org/10.1109/eespe63401.2025.10987180
-
S. Zheng, D. Li, Q. Yang, Y. Zhao, L. Jiang, and Z. Wang, “A log-normal complex-amplitude likelihood ratio-based TBD method with soft orbit-information constraints for tracking space targets with space-based radar,” IEEE Transactions on Radar Systems, Vol. 3, pp. 467–482, Jan. 2025, https://doi.org/10.1109/trs.2025.3546213
-
J. Chen, “Reliability and maintenance for systems with individually repairable components degrading as gamma processes,” Rutgers the State University of New Jersey, School of Graduate Studies, 2019, https://doi.org/10.7282/t3-3z01-py07
-
Z. Yang, “Maximum likelihood predictive densities for the inverse Gaussian distribution with applications to reliability and lifetime predictions,” Microelectronics Reliability, Vol. 39, No. 9, pp. 1413–1421, Sep. 1999, https://doi.org/10.1016/s0026-2714(99)00085-2
-
G. Medyna, S. Nonsiri, E. Coatanéa, and A. Bernardb, “Modelling, evaluation and simulation during the early design stages: Toward the development of an approach limiting the need for specific knowledge,” Journal of Integrated Design and Process Science, Vol. 16, No. 3, pp. 111–131, 2012, https://doi.org/10.3233/jid-2012-0006
-
J. Banks, Discrete event system simulation. Pearson Education India, 2005.
-
R. K. Phanden, P. Sharma, and A. Dubey, “A review on simulation in digital twin for aerospace, manufacturing and robotics,” Materials Today: Proceedings, Vol. 38, pp. 174–178, Jan. 2021, https://doi.org/10.1016/j.matpr.2020.06.446
-
A. Azadeh, M. Sheikhalishahi, and F. Monshi, “Selecting optimum maintenance activity plans by a unique simulation-multivariate approach,” International Journal of Computer Integrated Manufacturing, Vol. 29, No. 2, pp. 1–15, Mar. 2015, https://doi.org/10.1080/0951192x.2014.1003409
-
H. Ranjbar, H. Assimi, S. A. Pourmousavi Kani, and W. L. Soong, “Frequency-constrained autonomous microgrid planning for mining industry applications,” SSRN, 2025, https://doi.org/10.2139/ssrn.5132495
-
Y. Song, C. Yu, C. Magazzino, and X. Li, “Transitioning the mining industry to a greener economy: An Asian perspective of mineral demand,” Resources Policy, Vol. 102, p. 105483, Mar. 2025, https://doi.org/10.1016/j.resourpol.2025.105483
-
L. F. R. Camargo, L. H. Rodrigues, D. P. Lacerda, and F. S. Piran, “A method for integrated process simulation in the mining industry,” European Journal of Operational Research, Vol. 264, No. 3, pp. 1116–1129, Feb. 2018, https://doi.org/10.1016/j.ejor.2017.07.013
-
U. Chinbat and S. Takakuwa, “Using simulation analysis for mining project risk management,” in Proceedings of the 2009 Winter Simulation Conference (WSC), pp. 2612–2623, Dec. 2009, https://doi.org/10.1109/wsc.2009.5429647
-
J. R. Huerta, R. S. Silva, G. de Tomi, and A. L. M. Ayres Da Silva, “A dynamic simulation approach to support operational decision-making in underground mining,” Simulation Modelling Practice and Theory, Vol. 115, p. 102458, Feb. 2022, https://doi.org/10.1016/j.simpat.2021.102458
-
S. Chen et al., “Characterization of the porosity and permeability of gasified coal in ucg process: an experimental and simulation study,” ACS Omega, Vol. 10, No. 1, pp. 1308–1319, Jan. 2025, https://doi.org/10.1021/acsomega.4c08893
-
A. Crespo Marquez, “Modeling critical failures maintenance: a case study for mining,” Journal of Quality in Maintenance Engineering, Vol. 11, No. 4, pp. 301–317, Dec. 2005, https://doi.org/10.1108/13552510510626945
-
O. Golbasi and S. F. Sahiner, “Simulation-based optimization of workforce configuration for multi-division maintenance department,” SSRN, 2023, https://doi.org/10.2139/ssrn.4605874
-
X. Jiang, “Simulation model on the maintenance of mining equipment,” 2010.
-
H. Askari-Nasab, “Enhancing mining operations and productivity through discrete event simulation: a comprehensive literature review,” University of Alberta, Jan. 2024, https://doi.org/10.13140/rg.2.2.20564.31366
-
M. G. Raj, H. Vardhan, and Y. V. Rao, “Production optimisation using simulation models in mines: a critical review,” International Journal of Operational Research, Vol. 6, No. 3, p. 330, Jan. 2009, https://doi.org/10.1504/ijor.2009.026937
-
L. G. Koops, “Optimized maintenance decision-making – A simulation-supported prescriptive analytics approach based on probabilistic cost-benefit analysis,” European Conference, Vol. 5, No. 1, p. 14, 2020, https://doi.org/10.36001/phme.2020.v5i1.1269
-
T. Kono and K. Haneda, “Simulation-supported maintenance design and decision-making using agent-based modeling technology,” CIRP Annals, Vol. 70, No. 1, pp. 13–16, Jan. 2021, https://doi.org/10.1016/j.cirp.2021.03.014
-
A. Gosavi and A. Gosavi, “A simulation-based digital twin for data-driven maintenance scheduling of risk-prone production lines via actor critics,” Flexible Services and Manufacturing Journal, Vol. 38, No. 1, pp. 219–248, Nov. 2024, https://doi.org/10.1007/s10696-024-09579-1
-
R. Meissner, A. Rahn, and K. Wicke, “Developing prescriptive maintenance strategies in the aviation industry based on a discrete-event simulation framework for post-prognostics decision making,” Reliability Engineering and System Safety, Vol. 214, p. 107812, 2021, https://doi.org/10.1016/j.ress.2021.107812
-
A. A. Pohya, J. Wehrspohn, R. Meissner, and K. Wicke, “A modular framework for the life cycle based evaluation of aircraft technologies, maintenance strategies, and operational decision making using discrete event simulation,” Aerospace, Vol. 8, No. 7, p. 187, Jul. 2021, https://doi.org/10.3390/aerospace8070187
-
M. O. Turan and O. Golbasi, “Discrete-event simulation of a maintenance policy with multiple scenarios,” in International Symposium on Mine Planning and Equipment Selection, pp. 296–303, 2019, https://doi.org/10.1007/978-3-030-33954-8_37
-
H. Askari-Nasab, S. Upadhyay, E. Torkamani, M. Tabesh, and M. Badiozamani, “Simulation optimisation of mine operational plans,” in Orebody Modelling and Strategic Mine Planning Symposium, 2014.
-
E. B. Awuah, S. Kalantari, Y. Pourrahimian, and H. A. Nasab, “Hierarchical mine production scheduling using discrete-event simulation,” International Journal of Mining and Mineral Engineering, Vol. 2, No. 2, p. 137, Jan. 2010, https://doi.org/10.1504/ijmme.2010.035314
-
I. Soto, A. Anani, and E. Cordova, “A discrete event simulation approach for mine development planning at Codelco’s New Mine Level,” Journal of the Southern African Institute of Mining and Metallurgy, Vol. 122, No. 10, pp. 1–11, Nov. 2022, https://doi.org/10.17159/2411-9717/2045/2022
-
E. Tarshizi, C. Kocsis, and D. Taylor, “Advanced approach to assess and improve underground mine evacuation using discrete-event simulation and animation,” International Journal of Mining and Mineral Engineering, Vol. 7, No. 2, p. 170, Jan. 2016, https://doi.org/10.1504/ijmme.2016.076500
-
D. N. Murthy, M. Xie, and R. Jiang, “Weibull models,” in Series in Probability and Statistics, Wiley, 2003, https://doi.org/10.1002/047147326x
-
D. R. Cox, “Regression models and life-tables,” Journal of the Royal Statistical Society Series B: Statistical Methodology, Vol. 34, No. 2, pp. 187–202, 1972, https://doi.org/10.1111/j.2517-6161.1972.tb00899.x
-
D. R. Godoy, C. Mavrakis, R. Mena, F. Kristjanpoller, and P. Viveros, “Advancing predictive maintenance with PHM-ML modeling: optimal covariate weight estimation and state band definition under multi-condition scenarios,” Machines, Vol. 12, No. 6, p. 403, Jun. 2024, https://doi.org/10.3390/machines12060403
-
M. Kijima, “Some results for repairable systems with general repair,” Journal of Applied Probability, Vol. 26, No. 1, pp. 89–102, Jul. 2016, https://doi.org/10.2307/3214319
-
P. Wang, Z. Xu, and D. Chen, “An integrated framework for reliability prediction and condition-based maintenance policy for a hydropower generation unit using GPHM and SMDP,” Reliability Engineering and System Safety, Vol. 238, p. 109419, Oct. 2023, https://doi.org/10.1016/j.ress.2023.109419
-
S. Wu and D. Clements-Croome, “Optimal maintenance policies under different operational schedules,” IEEE Transactions on Reliability, Vol. 54, No. 2, pp. 338–346, Jun. 2005, https://doi.org/10.1109/tr.2005.847255
-
D. Wu, R. Han, Y. Ma, L. Yang, F. Wei, and R. Peng, “A two-dimensional maintenance optimization framework balancing hazard risk and energy consumption rates,” Computers and Industrial Engineering, Vol. 169, p. 108193, 2022, https://doi.org/10.1016/j.cie.2022.108193
-
C. Duan, V. Makis, and C. Deng, “An integrated framework for health measures prediction and optimal maintenance policy for mechanical systems using a proportional hazards model,” Mechanical Systems and Signal Processing, Vol. 111, pp. 285–302, Oct. 2018, https://doi.org/10.1016/j.ymssp.2018.02.029
-
M. Samrout, E. Châtelet, R. Kouta, and N. Chebbo, “Optimization of maintenance policy using the proportional hazard model,” Reliability Engineering and System Safety, Vol. 94, No. 1, pp. 44–52, 2009, https://doi.org/10.1016/j.ress.2007.12.006
-
M. Xie and C. D. Lai, “Reliability analysis using an additive Weibull model with bathtub-shaped failure rate function,” Reliability Engineering and System Safety, Vol. 52, No. 1, pp. 87–93, 1996, https://doi.org/10.1016/0951-8320(95)00149-2
-
D. Belyi, E. Popova, D. P. Morton, and P. Damien, “Bayesian failure-rate modeling and preventive maintenance optimization,” European Journal of Operational Research, Vol. 262, No. 3, pp. 1085–1093, Nov. 2017, https://doi.org/10.1016/j.ejor.2017.04.019
-
E. M. Assis, E. P. Borges, and S. A. B. Vieira de Melo, “Generalized q-Weibull model and the bathtub curve,” International Journal of Quality and Reliability Management, Vol. 30, No. 7, pp. 720–736, 2013, https://doi.org/10.1108/ijqrm-oct-2011-0143
-
D. Sillivant, “Reliability centered maintenance cost modeling: Lost opportunity cost,” in 2015 Annual Reliability and Maintainability Symposium (RAMS), pp. 1–5, Jan. 2015, https://doi.org/10.1109/rams.2015.7105111
-
R. E. Peimbert-Garcia, J. Limon-Robles, and M. G. Beruvides, “Cost of quality modeling for maintenance employing opportunity and infant mortality costs: An analysis of an electric utility,” The Engineering Economist, Vol. 61, No. 2, pp. 112–127, Apr. 2016, https://doi.org/10.1080/0013791x.2016.1152619
-
R. D. Frederiksen, G. Bocewicz, G. Radzki, Z. Banaszak, and P. Nielsen, “Cost-effectiveness of predictive maintenance for offshore wind farms: a case study,” Energies, Vol. 17, No. 13, p. 3147, Jun. 2024, https://doi.org/10.3390/en17133147
-
E. Byon and Y. Ding, “Season-dependent condition-based maintenance for a wind turbine using a partially observed Markov decision process,” IEEE Transactions on Power Systems, Vol. 25, No. 4, pp. 1823–1834, Nov. 2010, https://doi.org/10.1109/tpwrs.2010.2043269
-
C. Drent, S. Kapodistria, and J. A. C. Resing, “Condition-based maintenance policies under imperfect maintenance at scheduled and unscheduled opportunities,” Queueing Systems, Vol. 93, No. 3-4, pp. 269–308, Aug. 2019, https://doi.org/10.1007/s11134-019-09627-w
-
R. Zheng, B. Chen, and L. Gu, “Condition-based maintenance with dynamic thresholds for a system using the proportional hazards model,” Reliability Engineering and System Safety, Vol. 204, p. 107123, 2020, https://doi.org/10.1016/j.ress.2020.107123
-
S. More, W. Milne, and R. Tuladhar, “Multi-stage quantitative risk assessment of a critical system in mining industry,” Maintenance, Reliability and Condition Monitoring, Vol. 5, No. 2, pp. 172–195, Dec. 2025, https://doi.org/10.21595/marc.2025.24908
-
M. Ohring, “Failure and reliability of electronic materials and devices,” in Engineering Materials Science, San Diego: Elsevier, 1995, pp. 747–788, https://doi.org/10.1016/b978-012524995-9/50039-8
-
L. S. Martinez-Rau, Y. Zhang, B. Oelmann, and S. Bader, “On-device anomaly detection in conveyor belt operations,” arXiv, 2024, https://doi.org/10.48550/arxiv.2411.10729
About this article

This study is supported by the engineering department of James Cook University, Australia and Rockfield Technologies Pty Ltd, Australia.
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Sagar More: writing-original draft preparation, conceptualization, methodology. Daniel Grainger: writing-review and editing, conceptualization, methodology. Rabin Tuladhar: writing-review and editing.
The authors declare that they have no conflict of interest.
