Abstract
The information on unknown parameters of an oil formation can be express through a multivariate distribution of probabilities in space of parameters. A new quantitative method for carrying out of the discriminant analysis of models of an oil formation on the basis of hydrodynamic slits by sequential prediction of the probabilities of pressure modification is offered in this paper. Investigation of look-ahead probability for several models of the slit formation was conducted. The developed method can be used as a universal tool for carrying out of the discriminant analysis of models irrespective of the number of parameters.
1. Introduction
It is well known that confidence intervals are a convenient and good criterion for the adequacy of the chosen model. However, confidence intervals can sometimes lead to incorrect results. Moreover, they cannot establish a difference between the candidate models of the formation, since the models are characterized by different sets of parameters with the corresponding dimensions of the probability distributions. As a result, it is difficult to compare different models in the space of parameters. This paper describes a new quantitative method for discriminant analysis of models, which allows to overcome these difficulties. This method is a direct continuation of the methods for obtaining confidence intervals based on Bayesian inference. The idea of the method is that the correct model should more accurately predict the pressure changes than other models. From a quantitative point of view, the probability of a real change in pressure at future times for a correct model should be higher than the predicted probability for the remaining models. The predicted probability distribution of events associated with pressure changes can be calculated with known probability distributions of the parameters. Similar to the proposed approach, the methods are discussed in [1].
2. The structure of the algorithm
The basic algorithm of the method of sequential probability prediction (MSPP) for the discriminant analysis of reservoir models based on well test is as follows.
1) Select several candidate reservoir models that, in one way or another, are consistent with well test and other available information.
2) Use the first few results of pressure measurement to evaluate the reservoir parameters and predict the probability distribution for pressure at the next time point for each reservoir model.
3) Calculate the probability by substituting the actual pressure values in the formula for the predicted probability distribution and update the value of the total probability by multiplying it by the calculated probability with respect to each reservoir model.
4) Repeat the steps until a difference in the total probabilities for each reservoir model is achieved.
5) Discriminant analysis of reservoir model candidates is carried out based on the calculated total probabilities.
3. The mathematical model
The condition that the function describing the model can be approximated by expanding it in a Taylor series of the first order leads to the following expression:
where – a vector of of unknown parameters of layer, – the average (expected) values of parameters (an assessment of by a method of the smallest squares on the basis of of independent observations).
The predicted probability distribution for each model is determined in accordance with the following procedure in the Bayesian derivation. In this case, the parameters are considered random variables with some probability distributions.
Suppose that we know the variance of these distributions. Then the uncertainty associated with the model is described by the equation [2, 3]:
where is the pressure value for observation, is the Hessian matrix in the Gauss method [4]:
In this case, the parameters form a multidimensional normal distribution around with the covariance matrix with known independent observations of the pressure measurement results. is a dimension vector , and hence their probability distribution also has the dimension .
Using the and parameter estimates, the real pressure value at the point is expressed by Taylor expansion with the terms up to the first order:
The gradient of the model function is calculated at the point using the estimated values of the parameters based on the first observations.
Having chosen the notation , Eq. (4) can be represented in the form:
In accordance with Eq. (2), is normally distributed relative to with the predicted variance:
and conditional probability:
Eq. (8) characterizes the uncertainty associated with the model, which shows how adequate it is, and is completely determined by the average (expected) value of and the forecast variance .
The projected variance affects three important points. First, Eq. (7) shows that the forecast variance contains all information about the uncertainty concerning the parameters, since It is calculated using the covariance matrix . Second, it follows from the Schwartz inequality that the value of the predicted variance is limited by the determinant of the matrix :
The more information about the parameters received, the lower the uncertainty associated with them. The dimension of the multidimensional normal distribution becomes narrower, and the determinant of the covariance matrix decreases. Accordingly, the forecasted variance decreases. Therefore, when the multidimensional normal distribution for the parameters takes the form of the Dirac delta function [2], the normal distribution for the true pressure change relative to the predicted (expected) pressure change also narrows to the delta function. In other words, the uncertainty associated with the parameters is transformed into an uncertainty associated with a change in pressure. And, finally, more importantly, the predicted variance is a scalar quantity regardless of the dimensionality of the covariance matrix. Thus, models with a different number of parameters can be compared using predictive variance.
Fig. 1The relationship between Probyn+1*y^n+1, Probyn+1yn+1* and Probyn+1y^n+1
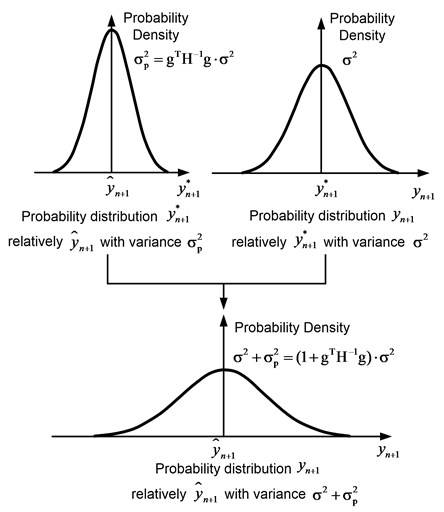
The uncertainty associated with the data is described as follows. Suppose that the observed change in pressure is normally distributed relative to the real pressure change with the variance :
Exactly the same assumption was made in the derivation of Eq. (2). Eq. (10) expresses the uncertainty associated with the data, which characterizes how well the model corresponds to the data.
Since the exact value of is unknown, the relationship between and is set by an exception in the integration by :
As a result, the observed pressure change is normally distributed with respect to the predicted (expected) pressure change with the overall predicted variance . This variance links the uncertainty of the model and the uncertainty in the data, as shown in Fig. 1.
4. Numerical simulations and results
The result of substituting the observed pressure change in Eq. (11) is the probability of observing at the moment for this model based on the first observations. This procedure is schematically shown in Fig. 2. Here the axis corresponds to the time, and the axis to the pressure.
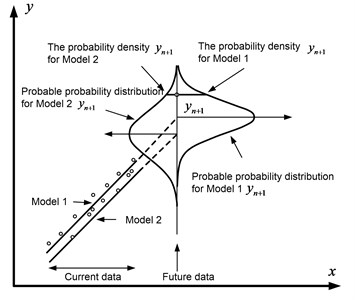
In Fig. 3 presents the probable probability distributions for the two models, which are designated as Model 1 and Model 2. It is seen that the probability of for the first model is higher than for the second. Therefore, Model 1 is more adequate than Model 2.
Fig. 2Schematic representation of the method of forecasting probabilities
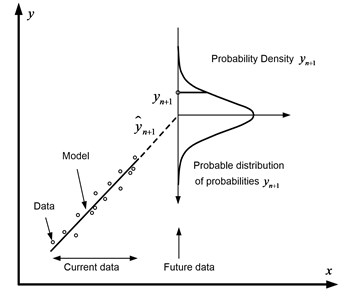
Fig. 3Schematic representation of the probability prediction method for two models
Eq. (11) indicates that the probability of observing at the moment will be the higher, the smaller the total predicted variance and the observed change in pressure closer to the predicted (expected) value of .
In Fig. 4 shows three possible cases for the two models. So, in Fig. 4(a), the expected pressure changes for the two models coincide, and the total predicted variances differ. In this case, the probability of observing for a model with a smaller variance will be higher. In Fig. 4(b), the expected pressure changes for the two models are different, and the overall predicted variances are the same. In this case, the probability of observing will be higher for a model in which the expected change in pressure is closer to its actual value. In Fig. 4(c) the expected pressure changes and the overall predicted variances differ. Then the probability of observing will be higher for a model that has a smaller variance and whose expected change in pressure is closer to its actual value.
Fig. 4Three possible cases of predictive probability distributions for two models
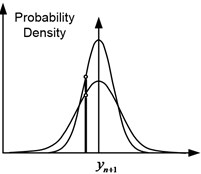
a) The same expected values, different variances
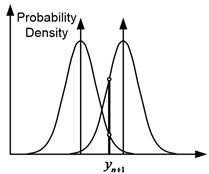
b) Different expected values, identical variances
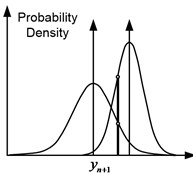
c) Different expected values, different variances
However, in cases where the actual change in pressure is closer to the expected value for a model with a larger overall predictive variance, this model will have a higher probability of observing at the time of . This suggests that this model, which has a large overall predictive variance at this stage, may prove to be a correct model in the future. That is, a sequential procedure is used to check whether this assumption is true [5].
In other words, substituting the actual pressure change in the formula for the predicted probability distribution for each model is the process of deciding which of the models is most appropriate at the current stage. In this case, the sequential procedure is the accumulation of the results of decision-making at all stages.
In the case when the variance is unknown, instead of Eq. (2) it is necessary to use equation:
Then Eq. (11) will be transformed to the form:
Thus, when the variance is unknown, forms an – distribution relative to with a total predictive variance of and degrees of freedom.
It should be noted that as the increases, the distribution becomes normal. Moreover, with instead of – distribution, it is entirely possible to use the corresponding normal distribution.
The projected variance plays a key role in MSPP. Typically, is smaller for a simpler model. To verify this, the probabilistic probability was studied for several reservoir models [6, 7]:
– radial flow in an infinite formation (three parameters: , and );
– with a non-conductive reset (four parameters: , , and );
– with an impenetrable outer boundary (four parameters: , , and );
– with constant pressure at the external boundary (four parameters: , , and );
– with double porosity and pseudo-stationary inter-porous flow (five parameters: , , , and );
– with double porosity, pseudo-stationary inter-porous flow and non-conductive reset (six parameters: , , , , and );
– with double porosity, pseudo-stationary inter-porous flow and impermeable outer boundary (six parameters: , , , , and );
– with double porosity, pseudo-stationary inter-porous flow and constant pressure at the outer boundary (six parameters: , , , , and ).
We studied the predictive probability characteristics for radial flow models in an infinite reservoir, a reservoir with a non-conductive discharge, a reservoir with an impenetrable outer boundary, and a reservoir with constant pressure at the outer boundary. From the point of view of the number of parameters, the flow model in an infinite reservoir was considered as a simple model, the rest as complex. In Fig. 5 shows the typical pressure variation curves and the corresponding values. Information on the formation and fluid: borehole radius 0.1 m, reservoir thickness 5 m, volume factor 1 [m3]reservoir/[m3]norm , viscosity 10-3 Pa·sec, porosity 0.2, initial pressure 20 MPa, total compressibility 10-4 MPa-1, operating rate 100 m3/day. The true values of the parameters are 0.05 µm2, and 0.2 m3/MPa. For reservoir models with a 600 m boundary. Pressure data was used without adding random errors. The total number of data points was 101. The Hesse inverse matrix was calculated using points at the moments from to . The gradient was determined at the point. changed from 41 to 100. The effect of the boundary is already noticeable from the moment of 20 h. In Fig. 5b oscillations in the values of for complex models are noticeable due to rejection errors caused by the applied method of numerical inverse Laplace transform. With the exception of the reservoir model with constant pressure at the outer boundary, the values of for the other complex models are always higher than for the simple model (the radial flow model in an infinite reservoir). Due to the boundary effects, the values of for the reservoir model with constant pressure at the outer boundary become less than for the radial flow model in the infinite formation.
Fig. 5The first study of predictive variance
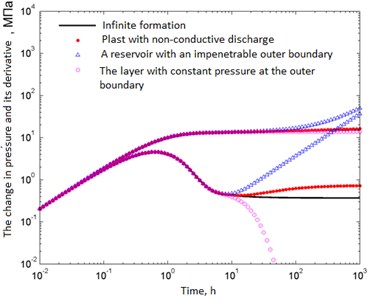
a)
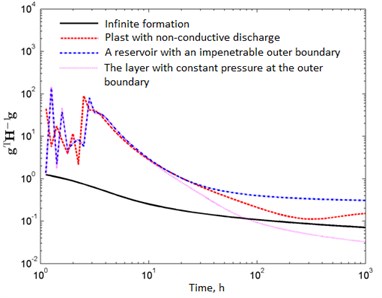
b)
5. Conclusion
On the basis of Fig. 5, we can conclude that for typical pressure variation curves the value decreases in the direction of simplification of the model.
The developed method provides a universal tool for discriminant analysis of models regardless of the number of parameters used. In this respect, the method compares favorably with methods based on confidence intervals, which cannot be used to compare models with different sets of unknown parameters. For example, it is not possible to directly compare the confidence intervals of permeability for two different models, such as the flow model in an infinite reservoir with three parameters () and the non-conductive four-parameter reservoir model (), because in the latter model, a strong negative correlation exists between and .
The method takes into account not only the diagonal elements of the inverse Hessian matrix, but also the elements outside the main diagonal, and therefore it uses all available information about the parameters by means of the predictive variance. It should be noted that methods based on confidence intervals take into account only the diagonal elements of the Hessian matrix.
This method meets the requirements of both the simplicity and complexity of the model. Theoretically, with an increase in the number of parameters, the overall correspondence of the model to the initial data increases due to a decrease in the number of degrees of freedom. However, the complication of the model reduces its predictable efficiency. This relationship is expressed quantitatively through and , which are components of the uncertainty associated with the model (). In general, it decreases with increasing complexity of the model, whereas decreases with the simplification of the model. In this case, the overall forecast variance takes into account both the simplicity and the complexity of the model.
The proposed method can simultaneously compare any number of reservoir models. Moreover, it is not required that any of the models be a subset of the other.
References
-
Anraku T., Horne R. N. Discrimination between reservoir models in well test analysis. SPE Formation Evaluation, Stanford University, Vol. 10, Issue 2, 1995, p. 114-121.
-
Gmurman V. E. Theory of Probability and Mathematical Statistics: Proc. Allowance. 12 Edition, Higher Education, Moscow, 2006, p. 479, (in Russian).
-
Ash R. Basic Probability Theory. Dover Publications, New York, 2008, p. 350.
-
Magnus J. R., Neidekker H. Matrix Differential Calculus with Applications in Statistics and Econometrics. John Wiley and Sons, Chichester, England, 2007, p. 468.
-
Gottman J., Roy A. Sequential Analysis: a Guide for Behavioral Researchers. Cambridge University Press, 1990, p. 275.
-
Vasilievsky V. N., Petrov A. I. Investigation of Oil Reservoirs and Wells. Nedra, 1973, p. 344, (in Russian).
-
Deeva T. A., Kamartdinov M. R., Kulagina T. E., Mangazeev P. V. Hydrodynamic Studies of Wells: Analysis and Interpretation of Data. Tomsk, 2009, p. 243, (in Russian).
About this article

