Abstract
Humanoid robots have a substantial potential to serve as teaching and social assistants. However, the expectations of the children from robots to interact like humans are huge. This study presents a general model for understanding the natural language in human-robot interaction by applying Generative Pre-trained Transformer (GPT) language models as a service in the Internet of Things. Thus, the physical presence of the robot can help in fine-tuning the GPT model by prompts derived from the environmental context and subsequent robot actions for embodiment understanding of the GPT outputs. The model uses web or cloud services for Natural Language Processing (NLP) to produce and play human-like text, question answering or text generation. Verbal questions are processed either via a local speech recognition software or via a Speech-to-Text (STT) cloud service. The converted question into machine-readable code is sent to one of the GPT language models with zero- or few-shot learning prompts. GPT-J model has been tested and deployed either in the web or cloud with options for varying the parameters for controlling the haphazardness of the generated text. The robot produces human-like text by using Text-to-Speech (TTS) cloud services that convert the response into audio format rendered on the robot to be played. Useful requirements how the model to be used in order to be feasible were determined based on the evaluation of the outputs given from the different NLP and GPT-J web or cloud-services. We designed and implemented the model in order to be used by a humanoid NAO-type robot in the speech language therapy practice, however it can be used for other open-source and programmable robots and in different contexts.
Highlights
- Presented is a general model for understanding the natural language in human-robot interactions by applying Generative Pre-trained Transformer (GPT) language model as a service in the Internet of Things.
- The model uses cloud services for IBM Watson Speech-to-Text and Text-to-Speech, and the EleutherAI GPT-J model for text generation in human-robot interactions.
- The physical presence of the robot help can in fine-tuning the GPT model by prompts from the environmental context derived by the robot sensory outputs and transmitted via Internet.
- An audio interface for EleutherAI GPT-J is designed and developed in Node-RED. It has been tested for making humanoid robots teaching assistants.
- The study contributes with research on how to define the right questions and parameters to GPT-J in order the output to make sense.
- The physical presence of the robot can be used for subsequent actions for embodiment understanding of the GPT outputs by integrating them into a real robot that can experience with 3D objects and teaching materials.
1. Introduction
The humanoid robots (HRs) have the biggest potential to support the special educational needs among the used assistive technologies in Special Education. They can play different roles: a play buddy, a mediator for interacting with other children or adults, a promoter of social interaction, an interest catcher in the teaching session [1]. The popular HRs used in the Special Education are described in [2]. Although they transfer children from the role of a spectator of the surrounding world into an active participant, their application is still limited, possibly due to lack of workable verbal interaction with humans. In the frame of the ongoing H2020 Project CybSPEED under Grant 777720EU we performed research experiments with a Speech and Language Therapy (SLT) system assisted by HRs to provide SLT intervention for children with communication disorders [3]. The obstacles we faced concerned the levels of robots’ verbal interactions. The expectation of the children from the two used humanoid robots to produce human-like text, question answering, text understanding and text generation were huge. The SLT professionals also claimed potential benefit from robot explanation of the SLT materials in case of incorrect child’s answer. Our idea for integration of AI-based services for Natural Language Processing (NLP) into interventions for Special Education is in line with the guidance how AI can be leveraged to enhance education in the UNESCO document [4]. AI applications to empower teachers and enhance teaching belong to one of the four need-based categories for the emerging AI applications to be designed [4].
NLP is a field of AI that gives the machines the ability to read text, listen words and understanding or generating text by deriving the meaning of the human languages. NLP applications have been used for language translations or for converting Text-to-Speech (TTS) and Speech-to-Text (STT) since long time ago. The new technology in the natural language generative tasks is the generative pre-trained transformer (GPT) language model. Such models are as OpenAI GPT-2 and GPT-3 [5], EleutherAI GPT-J and GPT-NEO [6], They are pre-trained with a huge amount of texts and can be used for language-related tasks such as text understanding, text generation, question answering, summarization, text sentiment analytics and chatbots. The models can be deployed locally, however the GPU and the computing resources require platform with hardware acceleration to handle huge deep learning workloads, thus using them as cloud services is recommended.
AI-enabled chatbots have been developed for teaching support, however for special education a chatbot or storyteller software on the screen might not be very interesting, engaging and motivating for a child to learn, listen and speak. Furthermore, children learn via multi-sensory inputs - audio, vision, touch, etc. Therefore, if a GPT language model is integrated with the AI elements of humanoid robot such as its mobility, responsiveness to touch, object recognition and other sensors inputs, the GPT may use additional tags/prompts for text interpretation of the current context. GPT-3 can generate text from data, i.e. input provided in a structured format such as: JSONs, web tables or knowledge graphs. After a wrong child answering, the conversation may start from the robot rather than from human as AI chatbots usually expect.
The present study examined the use of generative pre-trained transformers for making robots AI-assistants in order to enhance teaching. A general model for natural language understanding in human-robot interaction interface is proposed. It uses web or cloud services for NLP to produce and play human-like text, question answering or text generation. The model processes the verbal questions via a local speech recognition software or via a STT cloud service. The converted question into machine-readable code is after then sent to one of the GPT language models with zero- or few-shot learning prompts. The response is additionally filtered for inappropriate content locally or in the cloud. The robot produces human-like text by using TTS cloud services that convert the response into audio format rendered on the robot to be played. An open source node-based development tool built by IBM on Node.js - Node-RED [7] is used as integration environment. It wires devices and services using standard protocols and cross-platform server side runtime environment built in a browser. Node-RED has the potential to work in the IoT, which allow developers to easily integrate different NLP models into their code via web service calls of the model APIs. Useful requirements how the model to be used in order to be feasible were determined based on the evaluation of the outputs given by the different NLP and GPT-J web or cloud-services.
The results of this study will be useful in mass and special education, particularly in speech and language therapy. The generated by the model human-like text could be used to support children and adults in healthcare settings or in other situations where there is a need of social companion robots. The GPT services and the physical presence of the robot, working in the IoT, can help to fine-tune the GPT models by prompts derived from the robot sensory outputs and subsequent robot actions for embodiment understanding of the GPT outputs.
2. Literature review
Generative pre-trained transformer models, also known as Transformers, are auto-regressive language models that use deep learning for processing the context of the words (topic) and predict the next word based on the topic of all previous words within some text. They are pre-trained on huge data from the Internet and seek to set of distributions of topics for each document and to maximize the probability that a word belongs to a topic. Transformers divide the input text into “tokens” (words or characters) and measure the impact of the topic of the tokens - the more informative or more important tokens get larger weights for the sake of more attention. The topics are processed in parallel and attention mechanism is applied to predict the next token in the sentence based on the probabilities of the tokens in the text. OpenAI research laboratory created an open-source auto-regressive language model GPT-2 in 2019 with capacity of 1.5 billion machine learning parameters. In 2020, Open AI presented GPT-3 with 175 billion parameters, trained with almost all available data from the Internet. The innovation reported in [5] is that GPT-3 is a few-shot learner, in other words the fine-tuning of the model is done only by a few examples of the task in the prompt. One of the most advanced alternatives to GPT-3 are GPT-J-6B and GPT-J-NeoX of EleutherAI consisting of 20 billion parameters [6]. They are open-source models and both are few-shot learners.
Promising applications of Transformers in the educational domain are text generation, text summarization, “question and answer” tasks and sentiment analysis. However, limited applications of AI-enabled robots as teaching assistants have been proposed. Probably, one of the reasons is that GPT language models still lack common sense. A remarkable AI language machines can write like humans, however with no understanding of what they say [7]. Language makes sense to people and is not related only as letters written on a sheet of paper. Many AI-enabled chatbots have been developed to assist teaching but having no physical presence, the traditional disadvantage of learning technologies remains. This is the second reason for the need of AI-enabled robots, defined in [4] as physical machines that use AI techniques to interact with the word around. In the review presented in [8] authors described the lack of embodiment grounding processes when the existing Transformers were used for natural language understanding. Children learn by looking around, experiencing and acting. Therefore, multisensory inputs, such as vision, sound and touch need to be embodied in teaching. Some researchers think that Transformers might never achieve human-level common sense if they remain only in the field of language [9]. People do not absorb novel information by running statistics on word frequency, they understand how the world works, physically and socially [7]. The future lies in combining language models with declarative facts and possible ways to get common sense into language models, as foreseen in [7]. For example, GPT could be trained on YouTube clips for better reality understanding based on the moving images. In case of this passive augmentation is not enough, an army of robots need to interact with the world in order to collect declarative facts for the Transformers.
The used AI robots in education for children with learning difficulties has been explored in [10]. Speech-enabled humanoid robots for children with ASD have achieved outcomes similar to those of human tutoring on restricted tasks. Many works studied the use of GPT for extracting features from text to estimate the current emotional state, however this research has not been applied in the context of HRI interface. Humanoid robots should have the ability to interpret the affective cues and emotional response in the human sentences. Furhat (https://furhatrobotics.com/furhat-robot/) is an innovative social robot that has revolutionized human-robot interaction. It has the ability to customize its appearance by associating an unlimited number of characters through an innovative system for re-projecting and displaying a digital face on a same factory-produced physical mask. Furhat makes eye contact and shows emotions during speaking and listening. The robot comes with open source, which allows natural language processing and real-life emotional intelligence to be integrated into it. Furhat provides automated interactions in real-time by using the OpenAI GPT-3 model. Skills can be programmed and we consider that Furhat Library Skills – Card Game might be very useful to be applied in the special education for teaching multi-party and multi-modal social interactions. The robot and the children can solve problems together by using cards that have to be placed in a particular order with an option Furhat to be asked for advice. Learning by picture cards is one of the most commonly used techniques in speech and language therapy. However again, the physical embodiment of Furhat robot is not sufficient. Physical presence not only increases the robot acceptability. Physically embodied robot provides interlocutors with variety of sensory outputs, such as vision, audio, touch, smell, etc., which can be used for fine-tuning the GPT model. Instead of using few-shot learner, the GPT fine-tuning can be done by deriving the context around from the robot sensory outputs, such as 3D object recognition, tactile object recognition, sentiment in voice and others.
To conclude, implementing the NLP services via Transformers in HRI applications will be very helpful to improve the embodied dialogs by augmenting the GPT outputs via gestures and actions with real objects. The robot physical presence is still not used to derive the context for the environment around from the robot sensory outputs. We started to fill this gap by implementing GPT as a service for HRI in a tool working in the IoT, by which the robot can send the derived environmental context as prompt-words for GPT fine-tuning. Furthermore, the proposed model can be extended with subsequent robot actions for embodiment understanding of the GPT outputs by augmenting them with real or virtual experience through 3D objects and scenes. We also contributed with research on how to define the right questions and parameters to GPT in order the output to make sense.
3. A model for human-robot interaction interface using NLP web and cloud services
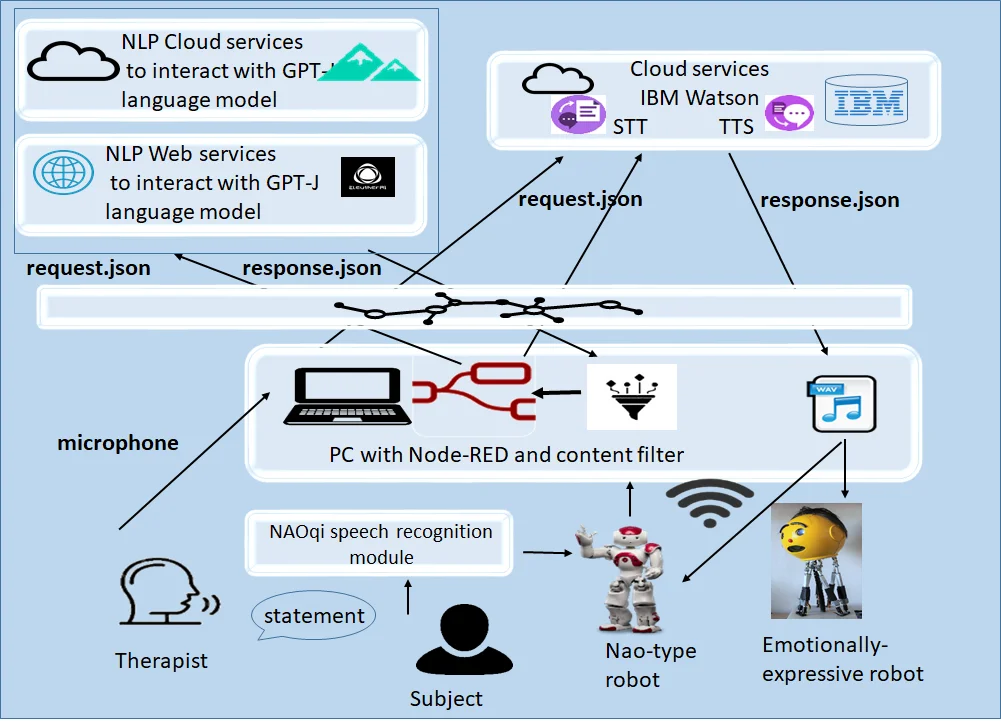
In this section, we describe the design, deployment and experiments how social robots to use web and cloud services for conversation, text completion and Q&A with GPT-J model. Fig. 1 illustrates the technologies underlying the proposed general model for natural language understanding in order the robot to understand, produce and play human-like text, question answering or text generation in the human-robot interaction. The used technologies are integrated by the Node-RED programming tool [11] - an open-source-node-based development tool designed by IBM on Node.js. It wires devices and services using standard and cross-platform open-source server-side runtime environment, built in a browser and provides a browser-based editor for wiring together flows. Nodes exchange data across predefined connections by message passing. The Node-RED has the potential to work in the IoT, which allow developers easily to integrate different NLP models into their code via web or cloud service calls of model APIs. Thus, we tested the integration of cloud-based services such as OpenAI GPT-2, GPT-3 [5], EleutherAI GPT-J [6], IBM Watson Assistant Solutions for TTS/STT [12] and Google translate/STT/TTS. Node-RED has designated nodes in its palette to access the web/cloud APIs services via nodes for HTTP POST request or for executing system command, such as cURL. The command is used to transfer data to or from a server without the user interaction.
Fig. 1A general model for natural language understanding in human-robot interaction using web/cloud services
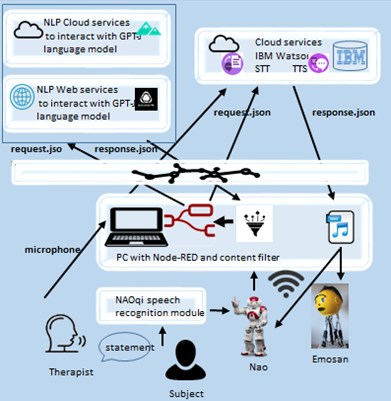
We designed and implemented the model to be used by a humanoid NAO-type robot of SoftBank Robotics in the speech language therapy practice. However, it can be implemented in other open-source and Python or ROS programmable robots and in different contexts. We transformed Nao robot into IoT device using the python processes in Node-RED and designed and deployed original Node-RED flows (Fig. 2) that allow flexible solutions for service calls of APIs for text translation, summarization, classification and other NLP scenarios. We tested the EleutherAI GPT-J model deployment in the web and cloud. We varied the model’s parameters for controlling the haphazardness of the generated text. By analogy the APIs of EleutherAI GPT-NEO, OpenAI GPT-2 or GPT-3 can be used in the proposed model.
Fig. 2The Node-RED flow for audio input to GPT-J for text generation
3.1. Programmable humanoid robots
Humanoid NAO robot and the emotion-expressive robot EmoSan are the devices using the Node-RED as a gateway to the IoT and cloud computing. With the proposed model we aim to lighten the robot computational resources for performing NLP tasks. Both robots NAO and Emosan are controlled and communicate in-between via the Node-Red. Therefore, the model can be integrated to one of them. The control systems of both robots read the Nao memory in one-second interval in order to trigger and synchronize their interactions. NAO reads and writes into its memory via python scripts inside Choregraphe (Softbank application for accessing NAOqi APIs via graphical language) or from a Node-Red node [3].
3.2. STT in Node-RED
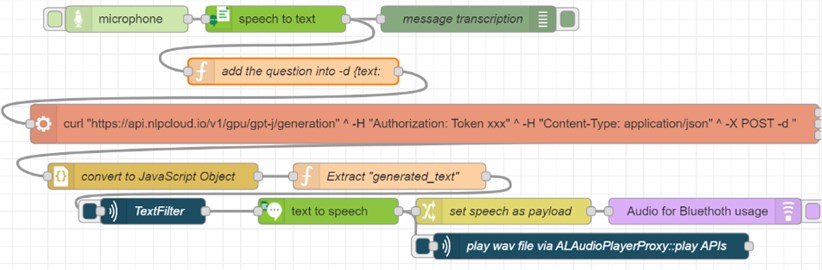
In the proposed model the question and the answer are performed by the IBM Watson Assistant via cloud STT and TTS services [12]. The audio gateway uses external services to convert speech to text and vice-versa. The STT engine parameters defaults to “Google” (however “Watson” can also be used) and provides modifying the sampling rate and the audio format. Watson STT and TTS have nodes in the Node-RED palette (the green nodes in Fig. 3(b)). A designated node for using Goggle services also exists (google-speech-text), however any other cloud or web STT and TTS services can be deployed by using http request node. How to edit the properties of this node is shown in Fig. 3(c). The authentication for type “bearer” needs to be chosen, where the user API token is requested. To post values to HTTP request node a change node is used where values are encoded in JSON format in Fig. 3(a).
Fig. 3Deployment of STT in Node-RED
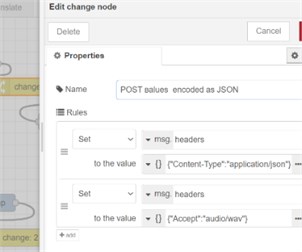
a) Properties for node change
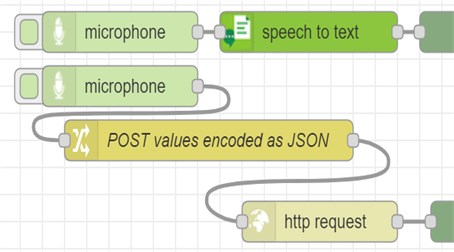
b) STT by Watson or http request nodes
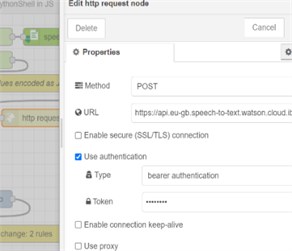
c) http request node properties
Fig. 4NLPcloud request in the Node-RED exec-node and its response

a) cURL in exec-node

b) Appending the question to exec node

c) NLPcloud response
3.3. Generative pre-trained transformer model in Node-RED
We used an open source GPT-J-6B – one of the alternatives to Open AI’s GPT-3. Its name comes from the use of JAX-based (Mesh) Transformer language model developed by a group of researchers from EleutherAI’s [6]. JAX is a Python library used extensively in machine learning experiments. The transformer model divided the text into “tokens” and measures the impact of the input data. The transformer model processes the input tokens in parallel and identifies the context in which a word in a sentence is used. In Node-RED we accessed GPT-J-6B via a web or a cloud service. First, we experimented with the GPT-J language model in Github (https://github.com/vicgalle/gpt-j-api, accessed on 15th of May 2022) that provides endpoints of the public API for GPT-J text generation (http://api.vicgalle.net:8000/, accessed on 14th of March 2022). Python streamlit or cURL can be used to access the web APIs. Then, we used the pre-trained models as a cloud service provided from the NLP Cloud (https://nlpcloud.io/). GPT-J language model is supported by the NLP Cloud. We access GPT-J APIs by the cURL command in exec-node in Node-RED (see Fig. 4(a)). The text of the question in JSON format is append as msg.payload to the exec-node in a proper cURL command format (Fig. 4(b)). For tuning the text generation we use the parameters “top_p” and “temperature” in the data requests. An example response obtained as a message payload from the exec node is presented in Fig. 4(c). Then the response is converted into JS object in order the generated text to be split and sent to the content filter. Its aim is to detect and filter profane and rude words. Currently, we are in process of integrating this filter by the python library called profanity-filter, which contains English lists of profane words.
3.4. TTS in Node-RED
The IBM Watson Assistant via cloud TTS services [12] is used for converting text into speech audio. Note, that other nodes such as the node for using Goggle services (google-tts) also exists. The voice, audio format and the sampling rate (the default is 16000 Hz) for Watson TTS audio client can be configured. Then the speech audio can be played in the browser and ready for a Bluetooth usage. The robot Emosan uses this approach. TTS service can create audio files in .wav or .ogg format which name is specified as a parameter of the node. The automatically recorded file is played by a NAO robot accessing the NAOqi APIs: ALAudioPlayerProxy:playFile from the pythonshell node in Node-RED.
3.5. Model validation, results and discussion
The experimental conclusions are based on the results obtained after deploying the model for text generation [13]. The software runs smoothly and could be applied by analogy for all NLP services provided by NLPcloud. Unfortunately, the latency delay is more than the normal (~100 ms) for a cloud-based service. We related this to the light payment plans that we used (free or pay-as-you-go). We didn’t test the fast GPT-J on GPU in NLPcloud, however for the specifics of the playful teaching scenarios in our project this delay is not critical for us. Furthermore, for faster respond to the GPT-J request the service can be used via an NLPcloud client libraries in Python, PHP, JS, C# and other programing languages, as well. We tested successfully NLPcloud services for Question answering in a piece of text, Summarizing text and Sentiment analysis. The sentiment results in a label and score, which via Node-RED can be sent to the emotional robot to be played. For faster STT, the symbolic STT of the NAO-type robot can be used (Fig. 5). We also have another reason for using it after studding in more details the outputs produced by the GPT-J and its limitations.
Fig. 5Simplified NAOqi STT method used by NAO robot
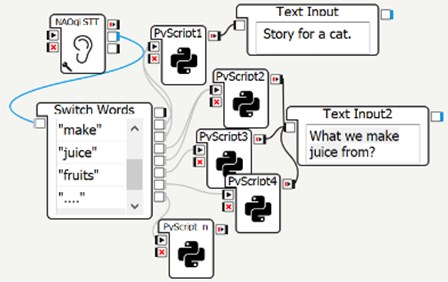
Due to the fact that GPT-J cannot answer complex, complicated or ambiguous questions, Eleuther AI offers two features which can be set: Temperature and Top-P. When we set the Temperature to a very low value, this means that the model chooses words that are more likely. The drawback is that setting Temperature to a very low value often makes the model to get stuck in loops. The Top-P value determines how many of the less probable words get excluded from the total samples. Thus, when it is set to a low value, more unlikely words are excluded. Top-P is another way of controlling the haphazardness of the generated text. We experimented with a question about what we can make juice from, because it is related to one of the teaching scenarios played between the robots and the child. We tested different questions in order to find the proper way for asking and receiving a reliable answer every time. We asked “What we make juice from?”. Table 1 and the supplemented video (https://youtu.be/4gctNTlbAmU) that validates the proposed model, demonstrate that we can perform a reasonable level of context generation by tuning GPT-J parameters. When the Temperature and Top-P are set to zero the answers of the GPT-J is normal, while a high Temperature and high Top-P mean strange, more surprising choice of words as in the second response to the same question.
Table 1Example for different responses to a question after tuning the GPT-J parameters
Question with tuning parameters | GPT-J answer |
What we make juice from? Temperature = 0 and TOP-P = 0 What we make juice from? Temperature = 1 and TOP-P = 0.9 | We make juice from the following fruits: Apple Apricot Blackberry Blueberry Cantaloupe Cherry Cranberry Grape Grapefruit Kiwi Lemon Lime Mango Orange …” The recipes in this blog are inspired by what we like to eat and drink. Due to being fed up with unhealthy food which we buy from chain stores. So change came into motion. RAPPOLOGY IS EATING JUICE TASTED GOOD (and colourful, healthy, economical and good for you) |
When GPT models generate content, we have always to keep our criticism because if it is prompted faithfully it can generate hate speech, racist and sexist stereotypes [7]. Our results are in line with the researchers that also have found risks that the models can produce malicious content [9]. One way of solving the problem is to extract malicious text from the pre-training data, but that provokes questions about what to exclude. It is important to know that Top-P provides better control for applications in which GPT-J is expected to generate text with precision and accuracy.
We plan to integrate the audio input to GPT-J into HRI within the speech language therapy system reported in [3]. It wires robots and services for speech language intervention in Node-RED. The approach can be extended to interface VR/MR devices for embodiment practice of the teaching content generated by GPT-J output.
4. Conclusions
Some limitations of the available techniques for using AI-based text generation in HRI stimulated this research on designing a model for practical usage of natural language in human-robot interaction. This paper introduces a new method for using NLP web or cloud services, which aims to lighten the robot computational resources for performing these tasks. The study examined the use of generative pre-trained transformers to make the robots AI-assistants in order to support teachers and enhance teaching. It was demonstrated that by tuning GPT-J parameters and asking the proper questions GPT-J can perform a reasonable level of text generation. The model is sufficiently general to be implemented for other GPT language models that have APIs call on one hand, and on the other hand deployed on variety of programmable robots and intelligent sensors. In the future we plan to use the physical presence of the robot for fine-tuning GPT-J-NeoX model of EleutherAI by prompts derived from the robot sensory outputs.
References
-
R. van den Heuvel et al., “The potential of robotics for the development and wellbeing of children with disabilities as we see it,” Technology and Disability, Vol. 34, No. 1, pp. 25–33, Mar. 2022, https://doi.org/10.3233/tad-210346
-
G. A. Papakostas et al., “Social robots in special education: a systematic review,” Electronics, Vol. 10, No. 12, p. 1398, Jun. 2021, https://doi.org/10.3390/electronics10121398
-
A. Andreeva, A. Lekova, M. Simonska, and T. Tanev, “Parents’ Evaluation of Interaction Between Robots and Children with Neurodevelopmental Disorders,” in Smart Education and e-Learning – Smart Pedagogy, pp. 488–497, 2022, https://doi.org/10.1007/978-981-19-3112-3_45
-
“AI and Education: guidance for policy makers. Education 2030,” UNESCO, 2021.
-
T. B. Brown et al., “Language models are few-shot learners,” in 34th Conference on Advances in Neural Information Processing Systems (NeurIPS 2020), 2020, https://doi.org/10.48550/arxiv.2005.14165
-
“EleutherAI GPT-J language model.”. https://www.eleuther.ai/
-
M. Hutson, “Robo-writers: the rise and risks of language-generating AI,” Nature, Vol. 591, No. 7848, pp. 22–25, Mar. 2021, https://doi.org/10.1038/d41586-021-00530-0
-
F. Röder, O. Özdemir, P. D. H. Nguyen, S. Wermter, and M. Eppe, “The embodied crossmodal self forms language and interaction: a computational cognitive review,” Frontiers in Psychology, Vol. 12, Aug. 2021, https://doi.org/10.3389/fpsyg.2021.716671
-
E. M. Bender, T. Gebru, A. Mcmillan-Major, and S. Shmitchell, “On the dangers of stochastic parrots,” in FAccT ’21: 2021 ACM Conference on Fairness, Accountability, and Transparency, pp. 610–623, Mar. 2021, https://doi.org/10.1145/3442188.3445922
-
T. Belpaeme, J. Kennedy, A. Ramachandran, B. Scassellati, and F. Tanaka, “Social robots for education: A review,” Science Robotics, Vol. 3, No. 21, Aug. 2018, https://doi.org/10.1126/scirobotics.aat5954
-
“IBM Node-RED.” 2022, https://developer.ibm.com/components/node-red.
-
“IBM Watson Assistant.”. https://www.ibm.com/docs/en/watson-assistant-s/version-missing?topic=advanced-configuring-stt-tts
About this article

This study was supported from the H2020 Project CybSPEED under Grant 777720EU and Regional Development Fund within the OP “Science and Education for Smart Growth 2014-2020”, Project CoC “Smart Mechatronic, Eco- And Energy Saving Systems And Technologies“, No. BG05M2OP001-1.002-0023.
