Abstract
Signals of short duration and containing a small number of cycles require special procedures if the precise estimation of their frequencies is intended. In this paper, we present an algorithm that allows accurate estimation of frequencies and simultaneously explains the decision regarding the prediction made. We first show why predictions regarding the frequency of signals mentioned above can contain significant errors and the prediction dependency on the analysis time. We then prove that the errors are systematic, and it is possible to train a neural network to quantify the errors and later correct the predictions. The algorithm also indicates the level of error by analyzing the signal-to-noise ratio. The algorithm was tested for numerous similar cases and proved to be reliable. At the end of the paper, we present how to use the algorithm using a signal generated with a known frequency.
1. Introduction
Analyzing the signals in the frequency domain is a common practice in structural health monitoring (SHM), which has proved its reliability [1]. Although the procedure seems simple, the accuracy of the results is unsatisfactory by applying standard methods such as DFT or FFT [2]. The low accuracy is achieved because the vibration signals resulting from impulsive excitation are short and contain few vibration cycles. Numerous researchers have tried to introduce interpolation methods to improve the estimation results and consequently obtain frequencies with a high level of precision [3]-[7]. A systematic review of these methods, which also quantify errors concerning the signal length, is presented in [8]. Zero-padding is a viable alternative to interpolation [9]. Trim-to-fit methods are also used for more accurate frequency estimation [2], [11]. However, the methods mentioned above do not yield highly accurate results.
This paper presents a method to estimate the frequencies based on the discrete Fourier Transform (DFT) property to produce systematically repeatable errors and a method involving artificial neural networks (ANN). In addition to other existing frequency estimation methods, this network also provides information regarding the accuracy of the estimation.
2. The origin of errors in standard frequency estimation
An analog sinusoidal signal has its time history expressed as follows:
In Eq. (1), is the signal amplitude, is the signal frequency, and is the length of the signal in the time domain. In the digital form, when sampling the signal with a sampling rate and using samples, the signal becomes a sequence:
Applying a standard DFT, the sequence is converted in the frequency domain. It results in amplitudes displayed on spectral lines numbered from 0 to –1. The value calculated for the -th line is:
Every can be decomposed into a real part , and an imaginary part , as follows:
In consequence, the -th spectral line will display the magnitude:
The spectral lines on which the amplitudes are displayed are equidistant. The distance between them is nominated as the frequency resolution. It is calculated according to the expression:
If is a multiple of the frequency resolution , thus:
with as a natural number, the true frequency is located on one of the spectral lines. At that spectral line, the actual amplitude of the signal will be displayed. The displayed amplitudes are zero on all other lines, meaning the true frequency was found. In Figure 1, we represent with red color the spectral line on which the true frequency is located.
The abovementioned case corresponds to the case where the signal has an integer number of cycles. It means the time length is a multiple periods of the sinusoidal signal. We can deduce this from the reversed Eqs. (7) and (8). These are:
Now, from Eq. (9), it directly results that:
Fig. 1The DFT represents a sinusoidal signal. The spectral lines for the standard DFT are represented with red lines having squares with a red contour on the tip; the additional squares represent the amplitudes of the supplementary spectral lines obtained by zero-padding (dashed lines); the magenta line with a blue square on the tip is associated with the actual frequency and is located on an inter-line position
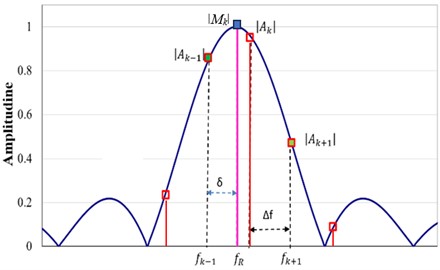
Hence, the spectral line number indicates the number of cycles present in the signal for the harmonic component with frequency . If k is not an integer, will be located at an inter-line position due to the positions of the spectral lines defined by the time length . In this case, the displayed amplitude is , smaller than the actual amplitude of the signal. Moreover, amplitudes will also be displayed on other spectral lines. On the neighbor spectral lines of , these amplitudes are and , plotted with a square having a red contour in Figure 1.
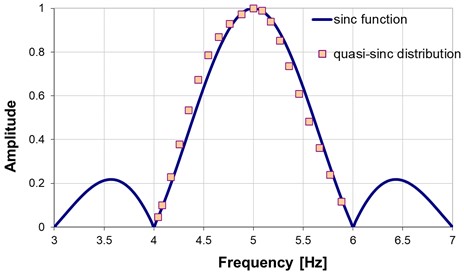
The distribution of when modifying the time length of the sinusoidal signal is quasi a function (Figure 2) centered on the real frequency or its spectral line if the spectrum is constructed using this approach. In order to have more points in the spectrum, we can lengthen the signal by adding points with zero amplitude, the so-called zero-padding [9]. If we double the number of samples, we obtain twice more spectral lines. The new amplitudes in the DFT represented in Figure 1 are marked with green squares with a red contour.
Fig. 2Comparison between the (quasi-sinc) distribution of Ak and the sinc function
One can observe in Figure 1 that the more dense spectral lines provide a better image of the shape of the function. We can also observe that the distance between the frequency displayed at line (i.e., ) and is the so-called correction term . We can write:
Hence, the normalized correction term can be calculated with the mathematical relation:
The following section proposes finding the correction term using an ANN model.
3. The methodology to create the ANN model and estimate correctly the frequency
The ANN is destined to find the correction term . The first step in developing the ANN model is to generate a sinusoidal signal with known frequency and amplitude. Using this signal, we develop a database containing the frequencies , , and the associated amplitudes , , , obtained using the DFT algorithm for different signal lengths. The crop is made by extracting two samples at iteration. For each set of data, we also calculate the correction term .
The generated sinusoidal signal has the amplitude = 1 and the frequency = 5 Hz. It is zero-padded to double its length. Initially, the entire signal has = 2155 samples taken by a frequency rate of =1000 Hz. Two samples are extracted by iteration, one from the sinusoid and one from the zero-padded end until the signal contains = 1925 samples. The longest signal time length is = 2.154 s, and the shortest is = 1.924 s. Figure 3 represents the amplitudes obtained in the DFT spectrum. We can observe the pattern for each cycle of time length . The amplitudes decrease with each cycle because less energy is contained in the shorter signal.
Fig. 3The amplitude Ak obtained for the signal by applying a standard DFT; the limits of the portion extracted for training are marked with arrows
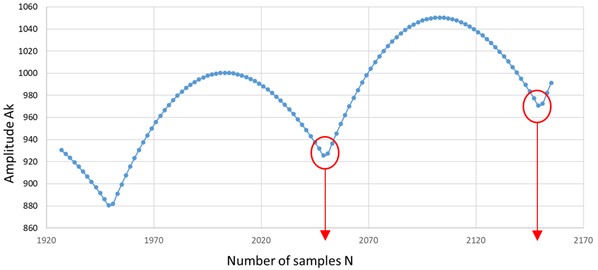
Based on the repeatability, it is enough to consider the data obtained by cropping one cycle, thus having a time length between – 0.5 (a minimum in the diagram in Figure 3) and + 0.5 (the following minimum in the diagram in Figure 3). So, we extract the portion of data contained between 2149 and 2051 samples. Aiming for the generalization, we do the following:
1. We normalize the amplitudes , , and obtained at each iteration by dividing them with the biggest amplitude achieved in the selected data set;
2. We normalize the calculated correction coefficient with the frequency resolution for each iteration separately.
An example of data with highlights on the training data (three input neurons and one output neuron) is given in Table 1.
Table 1Example of data used to create the training dataset
2149 | 2147 | 2145 | 2143 | 2141 | 2139 | ||
0.465 | 0.465 | 0.466 | 0.466 | 0.467 | 0.467 | ||
4.654 | 4.658 | 4.663 | 4.667 | 4.671 | 4.676 | ||
4.887 | 4.891 | 4.896 | 4.901 | 4.905 | 4.909 | ||
5.119 | 5.124 | 5.129 | 5.134 | 5.138 | 5.143 | ||
330.641 | 345.598 | 360.616 | 375.683 | 390.783 | 405.903 | Input data | |
970.866 | 977.306 | 983.488 | 989.412 | 995.078 | 1000.484 | Input data | |
962.558 | 952.333 | 941.808 | 930.994 | 919.902 | 908.547 | Input data | |
0.345 | 0.341 | 0.337 | 0.332 | 0.328 | 0.323 | ||
normalized | 1.485 | 1.465 | 1.445 | 1.425 | 1.405 | 1.385 | Output data |
With the data generated using the above procedure, we train a feed-forward backpropagation neural network with the architecture and main meta-parameters described in Figure 4.
Fig. 4Description of the deep neural network
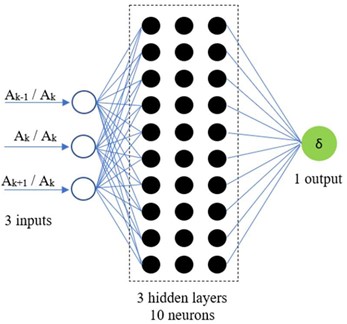
a) The network architecture
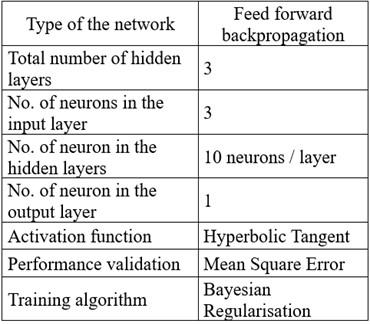
b) The main meta-parameters of the network
To avoid the phenomenon of network overfitting, we train the network by using the Bayesian Regularization function. The performance of the ANN reflected in the regression coefficients obtained after training is as follows: for Training and Validation 0.99847; for Test 0.997316; for the Cumulative data 0.9981. It means we obtained an excellent trained network.
After estimating the normalized correction term with the ANN model, we calculate the (estimated) frequency using the mathematical relation:
However, to explain why the prediction was made and if it is trustworthy, we add a follow-up to the standard use of the network. This step consists of the following:
1. Calculus of the period that corresponds to ;
2. Calculus of the signal length by multiplying with k;
3. Calculus of the amplitudes in the DFT of the reconstructed sinusoidal signal with length and frequency ;
4. Calculus of the signal-to-noise ratio.
The signal-to-noise ratio is used to prove the trustworthiness of the prediction. We calculate this parameter with the mathematical relation:
In Eq. (13), is the largest amplitude in the DFT with the length . The sum representing the denominator in Eq. (13) is the energy spread on the first spectral lines. The bigger the ratio, the better the frequency estimation. In the ideal case, = 1.
4. Validation of the proposed methodology
For validation, we use the original signal described at the beginning of Section 3. We calculate the amplitudes displayed at the first 24 spectral lines and identify the maximizer . The spectrum is presented in Figure 5 with a red line, and the relevant data regarding the signal and its DFT is given in Table 2.
Fig. 5The DFT of the original signal (red line) and truncated signal (blue line)
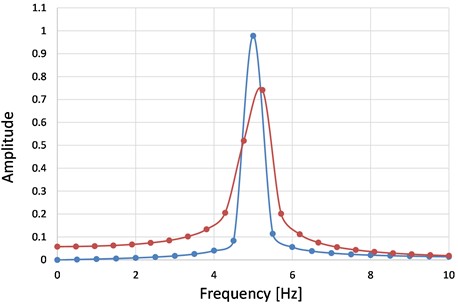
Afterward, we double the length of the signal by zero-padding and estimate the correction term δ involving the trained ANN. With this correction term, we calculate with Eq. (13) the fine estimation of the frequency, which is . It follows the calculus of and that of the length of the new signal with an entire number of cycles. The spectrum of this signal is represented in Figure 5 with a blue line. It is easily observable that the amplitudes in the red spectrum are spread along all spectral lines. Dissimilar, the blue spectrum is concentrated around the spectral line displaying the correct frequency, and on all other spectral lines, the amplitudes are small.
Table 2Example of data used to create the training dataset
Signal | ||||||||
Original | 2155 | 0.47619 | – | – | 5.238 | 0.7148 | 2.8194 | 0.2631 |
Truncated | 2103 | 0.5 | 4.7561 | 0.2439 | 5 | 0.9718 | 1.5659 | 0.6247 |
Table 2 presents the relevant data regarding the shortened signal and its DFT. We can observe that the fine estimation of the frequency is highly accurate, and the is significantly bigger for the signal with the tuned length calculated following . Therefore, the SNR is a clear indicator of the estimation accuracy, and it can be used to explain the decision of the AI system.
5. Conclusions
Automatic decision systems that rely on Artificial Intelligence must prove their decisions to be accepted by humans without hesitation. Thus, in addition to the results, the AI system should accompany the decision with data that a human can interpret. In this study, we show how the frequency estimation of signals can be improved by involving a machine-learning algorithm and propose using the SNR in a follow-up procedure to justify the decision.
Following the numerous experiments performed, one of which we presented in the paper, we noticed that the SNR is always the highest in the case of the correct frequency estimation. For even greater credibility, the system can be adjusted to calculate two more SNRs for a signal slightly more extended and one slightly shorter than the one considered correct. Both SNRs must present lower values than the SRN calculated for the correct estimation.
On the other hand, we demonstrated that using a Machine Learning algorithm, the frequency of the harmonic components of a signal can be estimated with excellent accuracy.
Future concerns will focus on estimating the frequencies of a signal with two close harmonic components.
References
-
H. Qarib and H. Adeli, “A comparative study of signal processing methods for structural health monitoring,” Journal of Vibroengineering, Vol. 18, No. 4, pp. 2186–2204, Jun. 2016, https://doi.org/10.21595/jve.2016.17218
-
D. Nedelcu and G.-R. Gillich, “A structural health monitoring Python code to detect small changes in frequencies,” Mechanical Systems and Signal Processing, Vol. 147, p. 107087, Jan. 2021, https://doi.org/10.1016/j.ymssp.2020.107087
-
V. K. Jain, W. L. Collins, and D. C. Davis, “High-Accuracy Analog Measurements via Interpolated FFT,” IEEE Transactions on Instrumentation and Measurement, Vol. 28, No. 2, pp. 113–122, 1979, https://doi.org/10.1109/tim.1979.4314779
-
P. Voglewede, “Parabola approximation for peak determination,” Global DSP Magazine, Vol. 3, No. 5, pp. 13–17, 2004.
-
J. R. Liao and S. Lo, “Analytical solutions for frequency estimators by interpolation of DFT coefficients,” Signal Processing, Vol. 100, pp. 93–100, 2014, https://doi.org/10.1016/j.sigpro. 2014.01.012
-
T. Murakami and W. Wang, “An Analytical Solution to Jacobsen Estimator for Windowed Signals,” in ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5950–5954, May 2020, https://doi.org/10.1109/icassp40776.2020.9053713
-
B. Gigleux, F. Vincent, and E. Chaumette, “Generalized frequency estimator with rational combination of three spectrum lines,” IET Radar, Sonar and Navigation, Vol. 16, No. 7, pp. 1107–1115, Jul. 2022, https://doi.org/10.1049/rsn2.12246
-
Andrea Amalia Minda, Constantin-Ioan Barbinita, and Gilbert Rainer Gillich, “A Review of Interpolation Methods Used for Frequency Estimation,” Romanian Journal of Acoustics and Vibration, Vol. 17, No. 1, pp. 21–26, Nov. 2020.
-
J. Luo, Z. Xie, and M. Xie, “Interpolated DFT algorithms with zero padding for classic windows,” Mechanical Systems and Signal Processing, Vol. 70-71, pp. 1011–1025, Mar. 2016, https://doi.org/10.1016/j.ymssp.2015.09.045
-
G. R. Gillich, I. C. Mituletu, Z. I. Praisach, I. Negru, and M. Tufoi, “Method to Enhance the Frequency Readability for Detecting Incipient Structural Damage,” Iranian Journal of Science and Technology, Transactions of Mechanical Engineering, Vol. 41, No. 3, pp. 233–242, Sep. 2017, https://doi.org/10.1007/s40997-016-0059-8
About this article

The authors have not disclosed any funding.
The datasets generated and analyzed during the current study are available from the corresponding author upon reasonable request.
The contribution of the authors is as follows: D.G. Burtea – Conceptualization, Formal Analysis, Investigation, Writing-Original Draft Preparation; G.-R. Gillich – Conceptualization, Supervision, Methodology, Writing-Review and Editing; C. Tufisi – Data Curation, Software, Visualization.
The authors declare that they have no conflict of interest.
