Abstract
This paper investigates the application of the Partly Ensemble Empirical Mode Decomposition (PEEMD), Principal Component Analysis (PCA) and Support Vector Machine (SVM) on signal processing, attribute reduction and pattern recognition. On this basis, a novel method for mechanical faulty diagnosis based on PEEMD, PCA and SVM is presented, which utilizes the PEEMD to extract faulty feature parameters from the statistical characteristics of intrinsic mode functions to constitute feature vectors, and then makes the attribute reduction by PCA method to obtain the key features, lastly these key features are input into GA-optimized SVM to accomplish faulty pattern recognition. The experimental results of the proposed method to fault diagnosis of the rolling bearing and stern bearing on marine propulsion shaft system show that this method can extract the faulty features, which have better classification ability and at the same time reduce the computation complexity significantly, accordingly improve the classifier efficiency and achieve a better classification performance.
1. Introduction
By reducing costs and decreasing the repair time, condition based maintenance becomes an efficient strategy for ship industry [1]. Marine propulsion shaft system is the key components of the ship power system. It influences directly the operation of the whole ship. Therefore, it is significant to be able to accurately and automatically detect and diagnose the existence and severity of the faults occurring in the marine propulsion shaft system. Since vibration signals carry a great deal of information representing mechanical equipment health conditions, the vibration based signal processing technique is one of the principal tools for diagnosing bearing faults [2, 3].
Typically, a fault diagnosis system contains two steps. The first step is to extract fault features by signal processing; the second step is to diagnose the faults by the characteristic information obtained in the first step. With the signal processing techniques, faulty characteristic information can be extracted from the vibration signals [4]. Considering the nonstationary of the Marine propulsion shaft system, the time frequency analysis methods such as Wavelet Transform (WT) [5, 6] and Empirical Mode Decomposition (EMD) [7] were used for processing the complex signal. EMD method [8] introduced by Huang et al. is an innovative time-series analysis tool in comparison with traditional methods such as Fourier methods, wavelet methods, and empirical orthogonal functions. A nonstationary and nonlinear signal will be decomposed into several Intrinsic Mode Function (IMF) components by sifting process of EMD. The result is a set of nearly orthogonal functions and the number of functions in the set depends on the original signal [9]. One of the primary weaknesses of EMD method is the phenomenon of mode mixing, which is defined as either a single IMF containing different scales signal, or a signal of a similar scale existing in different IMF components. In order to overcome shortcomings of EMD, a noise-assisted data analysis method called Ensemble EMD (EEMD) was proposed in [10] by adding white noise to initial data. The IMFs derived from EEMD, however, would inevitably be polluted by the added noise especially when the number of trials was in appropriate and this can be really true when reconstructing the original signal from the obtained IMFs. Recently, an enhanced EEMD algorithm called Complementary EEMD (CEEMD) was proposed to improve the efficiency of the original noise assisted method by adding noise in pairs with plus and minus signs [11]. However, in EEMD and CEEMD methods, the ensemble process is time-consuming especially when the number of trials is large. Moreover, the IMFs derived from EEMD and CEEMD often include some false and meaningless IMF components and some of them even do not meet the IMF definition conditions. In older to overcome these disadvantages of EEMD and CEEMD, another noise-assisted method Partly Ensemble EMD (PEEMD) is proposed in [12]. PEEMD decomposes a signal in a CEEMD way in the first ith IMFs and then using EMD in the remaining ranks, instead of implementing ensemble and averaging to all IMFs. Hence, PEEMD can reduce the amounts of calculation of CEEMD and improve the accuracy of obtained IMFs greatly.
Generally the vibration signals are obtained from the monitoring mechanical equipment. After the signal decomposed into several IMFs through PEEMD method, the statistical features like energy and kurtosis can be calculated to describe the characteristics of the signal at each frequency band. These statistical features can be utilized in the fault diagnosis directly, but in practice some of the features extracted from experimental data are usually imperfect and redundancy, even incompatible for each other, accordingly bring forth a lot of problems to mechanical fault diagnosis such as high computational complexity, low recognition speed and weak recognition effect. So it is meaningful to investigate the fault diagnosis method using the less attribute values without missing any fault information.
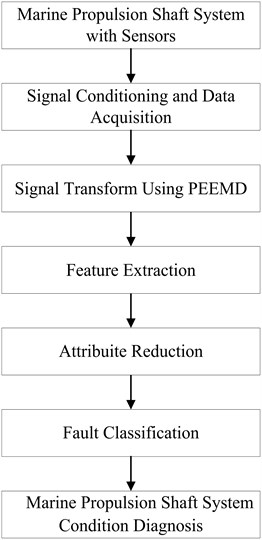
Fig. 1Flow diagram of the proposed fault diagnostic procedure
Principal Component Analysis (PCA) is a well-established method for feature extraction and dimensionality reduction [13]. PCA can be used to represent the d-dimensional data in a lower-dimensional space which will reduce the freedom degrees, the space and time complexities. The objective is to represent data in a space that best expresses the variation in a sum-squared error sense. This technique is mostly useful for segmenting signals from multiple sources. Recently, the principal component analysis has been widely applied in machine fault diagnosis domain [14, 15].
In recent years, SVM has been widely used in many research areas, such as face recognition, signal and image processing and fault diagnosis. SVM based classifiers have better generalization properties than ANN based classifiers [16, 17]. The efficiency of SVM based classifier does not depend on the number of features. This property is very useful in fault diagnostics because the number of features to be chosen is not limited, which make it possible to compute directly using original data without pre-processing them to extract their features. These advantages make SVM an excellent choice for the fault detection and localization applications [18]. Meanwhile, SVM kernel function parameters selection problem is an important factor affecting the performance of classification ability, Genetic Algorithm (GA) was used for optimizing the kernel function parameters.
According to the above principles, a new fault diagnosis method for marine propulsion shaft system is proposed in this paper, which utilizes the PEEMD to extract faulty feature parameters and then makes the attribute reduction in the faulty feature vectors by PCA method to obtain the key features, lastly these key features are input into SVM to accomplish faulty diagnosis. The flow diagram of the presented fault diagnosis method is shown in Fig. 1.
The following of this paper is organized as follows: in Section 2, the statistics parameters of the IMF components are extracted as faulty features by PEEMD. In Section 3, GA-optimized SVM is used to accomplish the fault pattern classification based on the selected features. In Sections 4 and 5, the proposed method is applied to diagnose different conditions of a rolling bearing and stern bearing on marine propulsion shaft system, and the results have verified the validity of the proposed diagnosis method. At last the conclusions have been briefly drawn in Section 6.
2. PEEMD method
By using EMD a complex signal can be decomposed into finite IMFs and a residual item. However, the main problem of EMD is the phenomenon of mode mixing. Aim to this, EEMD is proposed by adding different white noises to the targeted signal. The IMFs derived from EEMD would inevitably be polluted by the added noise. And CEEMD is presented mainly with the aim to decrease the reconstruction error caused by the added white noises. Unlike EEMD, in CEEMD white noises are added in pairs to the original data (i.e. one positive and one negative) to generate two sets of ensemble IMFs. Yet CEEMD and EEMD mainly have the following problems. First, the ensemble process is time-consuming especially when the number of trials is large. Second, the IMFs derived from EEMD and CEEMD often include some false and meaningless IMF components and some of them even do not meet the IMF definition conditions. This is mainly caused by the fact that different noise-added data may generate different number of IMFs, though adding white noise with the same size.
In order to avoid the defects of EEMD and CEEMD, another noise-assisted method partly ensemble EMD is proposed, which decomposes a given signal in a CEEMD way in the first (1)th IMFs and then using EMD in the remaining ranks, instead of implementing ensemble and averaging to all IMFs. Hence, PEEMD can reduce the amounts of calculation of CEEMD and improve the accuracy of obtained IMFs greatly. PEEMD is described as follows [12, 19].
(1) Suppose 1, add white noise series and to the targeted signal as:
where is the amplitude of added white noise, 1, 2,…, ; is the pair number of added white noise. In EEMD Wu and Huang suggested [10] to use small amplitude values for data dominated by high-frequency signals, and vice versa. Hence, they recommended that could be chosen about a few hundred, and the amplitude of added white noise was set about 0.2, where was the standard deviation of the targeted data. The was set 100 and parameter was set 0.2 in this paper.
(2) Decompose the two signal series and using EMD in the th IMF mode, and two IMF sets and can be obtained, as well as two residue sets and , respectively.
Namely:
(3) Through ensemble the final IMF in the th rank can be derived by:
(4) Calculate the Permutation Entropy (PE) of , if is larger than , then 1, and go to steps (2)-(3); if is smaller than , then go to step (5).
As PE is defined to measure the randomicity and dynamic change of time series, according to the experiments in [12], a recommended value of ranges from 0.5 to 0.6 and in this paper we set 0.6.
(5) Separate the first 1 IMFs from the original signal and the residue is obtained by:
(6) Decompose completely by using EMD:
(7) are regarded as the IMFs following to the first 1 IMFs. The initial signal is informed as:
PEEMD decomposes a given signal in a CEEMD way in the first (1)th IMFs and then using EMD in the remaining ranks, instead of implementing ensemble and averaging to all IMFs. In order to clarify the decomposition processes, consider the case of the signal as:
The time domain waveforms of , , and their mixed signal are showed in Fig. 2. The decomposing results of the mixed signal are given in Figs. 3-6, respectively.
Fig. 2The time domain waveforms of x1(t), x2(t), n(t) and their mixed signal x(t)
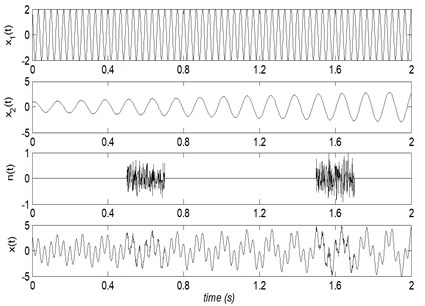
Fig. 3EMD decompose results of the mixed signal x(t)
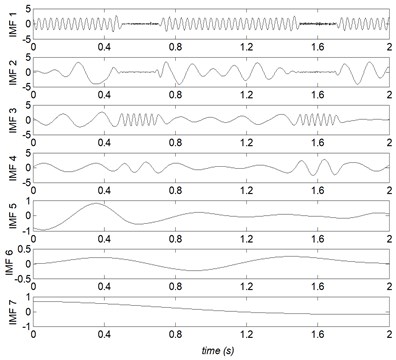
Fig. 4EEMD decompose results of the mixed signal x(t)
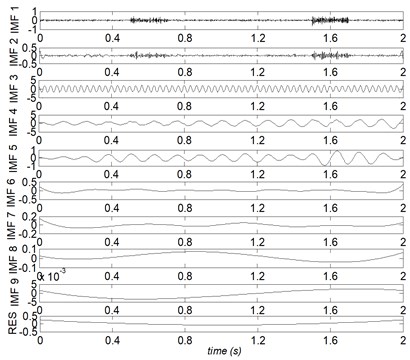
Fig. 5CEEMD decompose results of the mixed signal x(t)
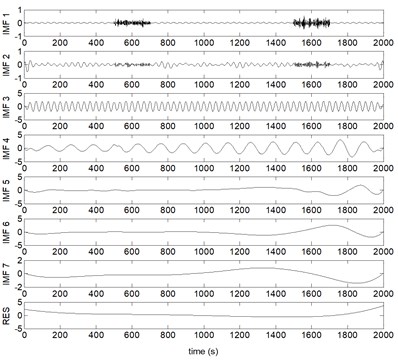
Fig. 6PEEMD decompose results of the mixed signal x(t)
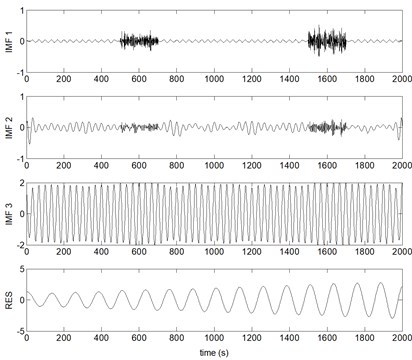
Where IMF represents the th IMF, and RES stands for the residual, correspondingly. From Figs. 3-6, it can be found that, due to the noise interference, EMD has emerged severe mode mixing and yielded false components without physical meanings. EEMD and CEEMD have similar decomposing results and both of them restrain the phenomenon of mode mixing effectively. The sum component IMF 1 and IMF 2 corresponds to the real component . However, and are divided into seven and five components by EEMD and CEEMD respectively. PEEMD performed well with a zero residue and the components IMF 3 and IMF 4 (RES) are in excellent agreement with the real component and .
3. SVM method
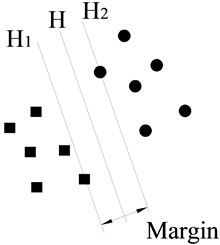
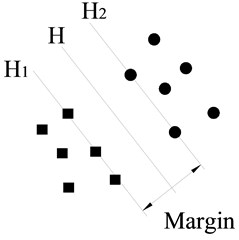
SVM is a statistic machine learning technique proposed by Vapnik [20] and widely used in pattern recognition. Let be a training sample set and each sample belongs to a class defined by . The goal of SVM is to find a hyperplane which divides , such that all the points with the same label are on the same side of the hyperplane while maximizing the distance between the two classes I, II and the hyperplane. An example of the optimal hyperplane of two data sets is presented in Fig. 6.
Fig. 7a) A separating plane with small margin and b) a separating plane with larger margin
a)
b)
As shown in Fig. 7, rings and diamonds stand for these two classes of sample points respectively; is a separating plane. and are planes that are parallel to and, respectively, pass through the sample points closest to in these two classes. The distance between and is defined as margin.
For linearly separable data, it is possible to determine a hyperplane that separates the data leaving one class on each side of the hyperplane. This plane can be described by the Eq. (7):
where is weight vector and is a scalar. The vector and the scalar determine the position of the separating hyperplane. The separating hyper plane should satisfy the constraints:
Positive slack variables are introduced to measure the distance between the margin and the vectors that lie on the wrong side of the margin. Then, the optimal hyper plane separating the data can be obtained by the following optimization problem:
where is the error penalty parameter. By introducing the Lagrangian multipliers , the above-mentioned optimization problem is transformed into the dual quadratic optimization problem, that is:
Thus, the linear decision function is created by solving the dual optimization problem, which is defined as:
SVM can also be used in nonlinear classification by using kernel function. By using the nonlinear mapping function , the original data are mapped into a high-dimensional feature space, where the linear classification is possible. Then, the nonlinear decision function is:
where is called the kernel function, .
Any function that satisfies Mercer’s theorem can be used as a kernel function to compute a dot product in feature space. There are different kernel functions used in SVMs, such as linear, polynomial and Gaussian RBF. The selection of the appropriate kernel function is very important, since the kernel defines the feature space in which the training set examples will be classified.
In order to apply SVM in mechanical fault diagnosis, there are two aspects of problems to study. Firstly, we can construct a multi-classifier by combining several binary classifiers for SVM is a binary classification method. Several methods have been proposed, such as ‘one-against-one’ (OAO), ‘one-against-all’ (OAA), and directed acyclic graph SVMs (DAGSVM) [21], where Hsu make a comparison of these methods and point out that the ‘one-against-one’ method is more suitable for practical use than other methods. In this study, we employ ‘one-against-one’ method to diagnose the different faulty condition. Secondly, the radial basis function kernel is selected and the Genetic Algorithm (GA) algorithm [22] is adopted for SVM model generalization parameter selection and searching proper RBF kernel parameter width .
4. Experimental setup and data acquisition
To demonstrate the performance of the proposed fault diagnosis method, two kinds of experimental setups are presented in this section for offering the vibration signals from various faulty conditions of rolling bearings and stern bearing on a marine propulsion shaft system.
4.1. The rolling bearing experiment
The experimental setup consists of a 2 hp motor, a torque transducer, a dynamometer and control electronics. The test bearings support the motor shaft [23]. Motor bearings are seeded with faults using Electro-Discharge Machining (EDM). Faults ranging from 0.007 inches in diameter to 0.040 inches in diameter are introduced separately at the inner raceway, rolling element and outer raceway. Faulted bearings are reinstalled into the test motor and vibration data is recorded for motor loads of 0 to 3 horsepower (motor speeds of 1797 to 1730 RPM). Vibration data is collected using accelerometers, which are attached to the housing with magnetic bases.
Fig. 8Schematic diagram of the propulsion shaft system experiment setup
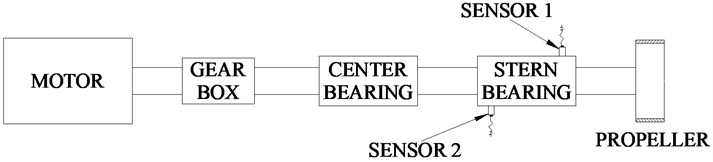
4.2. The propulsion shaft system experiment
The second experiment is to identify different conditions of stern bearing on a propulsion shaft system. As shown in Fig. 8, the test stand consists of a motor, a gear box, a center bearing, a stern bearing and a propeller. The test stern bearing support the propulsion shaft. Several typical faulty conditions of the stern bearing are simulated, such as parallel misalignment being too large and the angular misalignment being too large. Five states including four faulty states and one normal state of stern bearing are tested. The description of the five states of stern bearing is shown in Table 1.
Table 1Five states of stern bearing on propulsion shaft system
Condition code | Faulty description | |
C-1 | Normal condition | |
C-2 | Parallel horizontal misalignment being too large | Horizontal offset 2.5 mm |
C-3 | Parallel vertical misalignment being too large | Vertical offset 2.5 mm |
C-4 | Angular horizontal misalignment being too large | The aft of bearing horizontal offset 3 mm |
C-5 | Angular vertical misalignment being too large | The aft of bearing vertical offset 3 mm |
The diameter of the stern bearing is 250 mm. In order to avoid the misalignment is too large which will destroy the propulsion shaft system or too small which will affect the test of faulty conditions, the parallel horizontal misalignment and parallel vertical misalignment are both set 2.5 mm. At the same time, the angular horizontal misalignment and angular vertical misalignment are set 3 mm. The parallel misalignment and angular misalignment are showed in the Fig. 9.
Fig. 9Schematic diagram of the parallel misalignment and angular misalignment

a) Parallel misalignment

b) Angular misalignment
Vibration data was collected using accelerometers, which were attached with rubber bases to the ends of stern bearing as showed in the Fig. 9. Accelerometers were placed at the 9 o’clock position and 3 o’clock position at the front end and rear end of the stern bearing. One group (20480 points) was collected per minute with a sampling rate of 25.6 kHz. 160 groups of each condition were collected, and 80 groups are used for training the SVM model and another 80 groups were adopted for testing.
5. Results and discussion
In order to identify different working conditions of the monitoring bearing and stern bearing on propulsion shaft system, the proposed fault diagnosis method mentioned above is performed.
Fig. 10The CEEMD decomposition results of rolling bearing vibration signal with rolling element defects in 1750RPM

5.1. Case 1: fault diagnosis of bearing
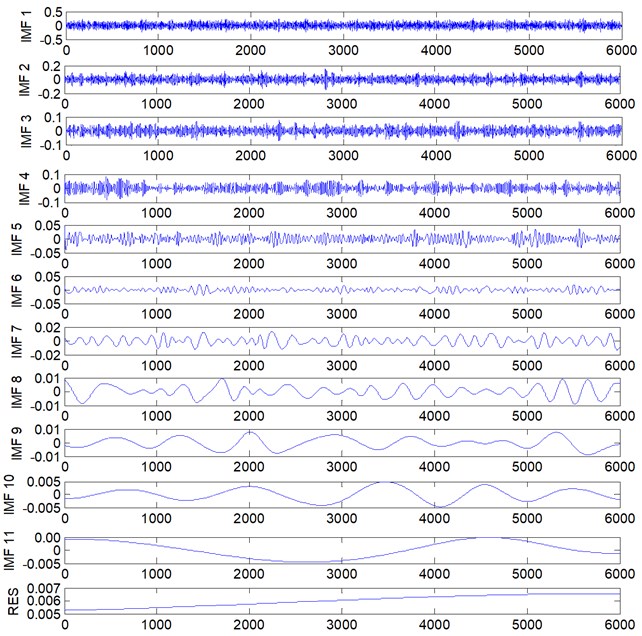
Firstly, the rolling bearing faulty signals are decomposed into several IMFs using PEEMD and CEEMD and the cost time are studied. The decomposition results of rolling element defects signal in 1750RPM through CEEMD and PEEMD are showed in Fig. 10 and Fig. 11, respectively. Since the IMFs of each signal are different and only the first IMFs contain the main faulty characteristic, the first five IMFs of each signal are selected. The statistical features, energy and kurtosis, of the five IMFs are calculated to construct a 10-dimensional feature vector. According to the faulty features classification method described in Section 3, the classification accuracies using all the PEEMD faulty features and using all the CEEMD faulty features are investigated. The results are listed in Table 2.
Table 2The feature extraction cost time (s) and fault diagnosis accuracies (%) of rolling bearing
Work load condition | Signal processing method | Cost time (s) | Classification accuracy |
Condition 1 (1750RPM) | CEEMD | 109.5 | 98.25 % |
PEEMD | 27.0 | 99.25 % | |
Condition 2 (1797RPM) | CEEMD | 105.9 | 98.50 % |
PEEMD | 29.2 | 99.75 % |
Fig. 11The PEEMD decomposition results of rolling bearing vibration signal with rolling element defects in 1750RPM
The results show that the calculating time of PEEMD save a great deal than CEEMD method. At the same time, the GA-optimized SVM recognition accuracies of using PEEMD faulty features are higher than using CEEMD faulty features. It indicates that the PEEMD method is more effective and need less calculating time than CEEMD method.
Meanwhile, considering the PEEMD faulty features, the recognition accuracies using all faulty features and using the extracted faulty features through PCA are researched. The results are listed in Table 3.
From Table 3, we can find that the recognition accuracies obtained using the selected faulty features through PCA are little more than those obtained using all faulty features.
Table 3The recognition accuracies (%) of rolling bearing obtained using all faulty features and using the selected faulty features through PCA
Work load condition | Classification accuracies using all features | Classification accuracies using selected features |
Condition 1 (1750RPM) | 99.25 % | 99.50 % |
Condition 2 (1797RPM) | 99.75 % | 100.00 % |
5.2. Case 2: fault diagnosis of stern bearing on propulsion shaft system
As showed in Fig. 7, there are two acceleration sensors attached in stern bearing for collecting the vibration signals. As the same in Section 5.1, the vibration signals are decomposed into several IMFs using PEEMD and CEEMD, and the calculating time are investigated. The statistical features, energy and kurtosis, of the first five IMFs are used to construct a 20-dimonsional diagnosis feature vector, respectively. According to the GA-optimized SVM classification method, the classification accuracies using all the PEEMD faulty features and PCA selected PEEMD faulty features; using all the CEEMD faulty features and PCA selected CEEMD faulty features are investigated. The results are listed in Table 4.
Table 4The recognition accuracies (%) of stern bearing on marine propulsion shaft system obtained using all faulty features and using the selected faulty features through PCA
Signal processing method | Cost time (s) | Features extracted | Features selected | Classification accuracies using all features | Classification accuracies using selected features |
CEEMD | 104.6 | 20 | 5 | 91.25 % | 92.25 % |
PEEMD | 29.7 | 20 | 5 | 93.50 % | 93.75 % |
From Table 4, we can get that the PEEMD method perform a lot than CEEMD method in calculating time and classification accuracies. It appears to be that the PEEMD method could overcome the defects of CEEMD and reduce computation complexity significantly. Moreover, the GA-optimized SVM diagnosis results indicate that the recognition accuracies of PCA selected faulty features are higher than using all features. The 20-dimensional vector is reduced to 5-dimensional feature vector, which indicate that the signals contain some useless and redundant information. And the PCA method can be used for feature extraction and dimensionality reduction effectively.
5.3. Discussion
In the rolling bearing experiment, the diagnosis accuracies of the proposed method mainly achieve 100 %. The results suggest that the proposed method is effective. We put forward the PEEMD and GA-optimized SVM diagnosis method in the marine propulsion shaft system at the first time. Results show that the classification accuracies achieve more than 93 %. We confirm that the PEEMD can surmount the limitation of the CEEMD and can reduce the computation complexity significantly. The 20-dimensional feature vector is reduced to 5-dimensional feature vector through PCA method, and the SVM diagnosis accuracies of PCA selected faulty features are higher than using all features. It seems that the PCA method perform well in feature extraction and feature dimensionality reduction. In addition, the proposed method based on PEEMD, PCA and GA-optimized SVM perform well in the rolling bearing and stern bearing of marine propulsion shaft system which indicate that the method is effective. It should be noted that comparing with the rolling bearing faulty states classification accuracies which are almost 100 %, the stern bearing faulty conditions recognition accuracies are no greater than 94 %. However, these problems can be solved if we consider the noise in the vibration signal collected from the stern bearing.
6. Conclusions
In this paper, a novel fault diagnosis method based on PEEMD, PCA and SVM is presented. Firstly, the PEEMD method is employed for decomposing the vibration signal into IMF components. And the statistical features, energy and kurtosis, of the IMF components containing main faulty features are calculated for constructing the feature vector. Secondly, PCA is adopted for feature vector dimensions reduction. Finally, the GA-optimized SVM method is used for faulty condition recognition. The features extracted by this method had better distinction ability and cost less time, so it is more effective in faulty condition diagnosis. The validity of the proposed fault diagnosis method is verified by the application of practical experiments of the rolling bearing and stern bearing in the propulsion shaft system.
References
-
Peng Z. K., Chu F. L. Application of the wavelet transform in machine condition monitoring and fault diagnostics: a review with bibliography. Mechanical Systems and Signal Processing, Vol. 18, 2004, p. 199-221.
-
Lei Y. G., et al. Fault diagnosis of rotating machinery based on a new hybrid clustering algorithm. International Journal of Advanced Manufacturing Technology, Vol. 35, 2008, p. 968-977.
-
Zarei J., Poshtan J. An advanced Park’s vectors approach for bearing fault detection. Tribology International, Vol. 42, Issue 2, 2009, p. 213-219.
-
Liu B., Riemenschneider S., Xu Y. Gearbox fault diagnosis using empirical mode decomposition and Hilbert spectrum. Mechanical Systems and Signal Processing, Vol. 20, Issue 3, 2006, p. 718-734.
-
Purushotham V., Narayanan S., Prasad S. A. N. Multi-fault diagnosis of rolling bearing elements using wavelet analysis and hidden Markov model based fault recognition. NDT&E International, Vol. 38, 2005, p. 654-664.
-
Li N., et al. Mechanical fault diagnosis based on redundant second generation wavelet packet transform, neighborhood rough set and support vector machine. Mechanical Systems and Signal Processing, Vol. 28, 2012, p. 608-621.
-
Wu F. J., Qu L. S. Diagnosis of subharmonic faults of large rotating machinery based on EMD. Mechanical Systems and Signal Processing, Vol. 23, 2009, p. 467-475.
-
Huang N. E., et al. The Empirical mode decomposition and the Hilbert spectrum for nonlinear and nonstationary time series analysis. Proceedings of the Royal Society of London, Vol. 12, 1998, p. 903-995.
-
Huang N. E., Shen S. S. P. Hilbert-Huang Transform and Its Applications. World Scientific Publishing, Singapore, 2005.
-
Wu Z., Huang N. E. Ensemble empirical mode decomposition: a noise assisted data analysis method. Advances in Adaptive Data Analysis, Vol. 1, Issue 1, 2009, p. 1-41.
-
Yeh J. R., Shieh J. S. complementary ensemble empirical mode decomposition: a novel noise enhanced data analysis method. Advances in Adaptive Data Analysis, Vol. 2, Issue 2, 2010, p. 135-156.
-
Zheng J. D., Cheng J. S., Yang Y. Partly ensemble empirical mode decomposition: an improved noise-assisted method for eliminating mode mixing. Signal Processing, Vol. 96, 2014, p. 362-374.
-
Guo Q., Wu W., Massart D. L., et al. Feature selection in principal component analysis of analytical data. Chemometrics and Intelligent Laboratory Systems, Vol. 61, 2002, p. 123-132.
-
Yuan Sheng-Fa, Chu Fu-Lei Support vector machines-based fault diagnosis for turbo-pump rotor. Mechanical Systems and Signal Processing, Vol. 20, 2006, p. 939-952.
-
Dong S. J., et al. A fault diagnosis method for rotating machinery based on PCA and Morlet kernel SVM. Mathematical Problems in Engineering, 2014, p. 1-9.
-
Samanta B., Al-Balushi K. R., Al-Araimi S. A. Artificial neural networks and support vector machines with genetic algorithm for bearing fault detection. Engineering Applications of Artificial Intelligence, Vol. 16, 2003, p. 657-665.
-
Samanta B. Gear fault detection using artificial neural networks and support vector machines with genetic algorithms. Mechanical Systems and Signal Processing, Vol. 18, 2004, p. 625-644.
-
Hsu C., Lin C. J. A comparison of methods for multi-class support vector machines. IEEE Transactions on Neural Networks, Vol. 13, Issue 2, 2002, p. 415-425.
-
Hu Q., He Z. J., Zhang Z. S., et al. Fault diagnosis of rotating machinery based on improved wavelet package transform and SVMs ensemble. Mechanical Systems and Signal Processing, Vol. 21, 2007, p. 688-705.
-
Zheng J. D., Cheng J. S., Yang Y. Modified EEMD algorithm and its application. Journal of Vibration and Shock, Vol. 32, Issue 21, 2013, p. 21-26.
-
Vapnik V. The Nature of Statistics Learning Theory. Springer Verlag, New York, 1995, p. 20-60.
-
Hsu C. W., Lin C. J. A comparison of methods for multiclass support vector machines. IEEE Transactions on Neural Networks, Vol. 13, Issue 2, 2002, p. 415-425.
-
Liu D.,Niu D. X., Wang H., et al. Short-term wind speed forecasting using wavelet transform and support vector machines optimized by genetic algorithm. Renewable Energy, Vol. 62, 2014, p. 592-597.
-
http://csegroups.case.edu/bearingdatacenter/pages/download-data-file.
About this article

This research is supported by Natural Science Foundation of China (Grant No. 51409238).
