Abstract
Aiming at the problem of operating state prediction of generator bearing, a prediction method based on quantum particle swarm optimization (QPSO) and united least squares support vector machine (ULSSVM) is proposed. Firstly, the time least squares support vector machine (TLSSVM) model is established in accordance with the change law of characteristic parameters over time. Space least squares support vector machine (SLSSVM) model is established in accordance with the law of mutual influence between characteristic parameters. Secondly, the QPSO algorithm is used to optimize the parameters of each least squares support vector machine (LSSVM) model. When the difference between the predicted value and the measured value reaches the minimum, the optimal LSSVM parameter set is output. Then the improved Dempster-Shafer (D-S) theory is used to determine the weights of TLSSVM and SLSSVM. A united model of time LSSVM and space LSSVM is established. The characteristic parameters are predicted. The prediction results and the reference matrix are fused and reduced in dimension. Finally, the generator bearing operating status is predicted based on the location of the prediction results. The results show that the proposed method is helpful to realize the operating state prediction of the wind turbine bearing.
Highlights
- ULSSVM, a novel parameter prediction method, is proposed to effectively predict the operating state parameters.
- Improved D-S method is used to determine the weight of each model. It helps ULSSVM achieve better results in the parameter prediction of wind turbine bearing.
- The novel strategy of utilizing combined ULSSVM and QPSO to parameter prediction in wind turbine bearing is developed.
1. Introduction
Wind turbine has been in a rapid growth mode since the 20th century. This rapid growth also affects the performance of wind turbines. The generator is one of the key components of the wind turbine [1]. Bearings are used in generators. The operating state of the bearing is not only related to the normal operation of the generator, but also related to the stable operation of the wind turbine [2]. The damaged bearings are often the leading cause of machine downtime and huge economic loss [3, 4]. Effectively predicting the operating status of the wind turbine generator can reduce downtime and economic loss.
Data prediction is significant for operating state prediction. Least squares support vector machine (LSSVM) is a commonly used method in data prediction [5-7]. However, this method often only considers the trend of a single characteristic parameter with time and does not consider the interaction between various characteristic parameters. In the prediction process, there are often correlations among various characteristic parameters. The change of a certain characteristic parameter will reflect or affect the change of other characteristic parameters to a certain extent. Aiming at this problem, a prediction method based united least squares support vector machine (ULSSVM) is proposed. ULSSVM method combines time least squares support vector machine (TLSSVM) model and space least squares support vector machine (SLSSVM) model. The TLSSVM model is established based on the law of characteristic parameters changing with time. The SLSSVM model is established based on the relationship between the characteristic parameters. In the training phase of the model, the original data sequence is used as input. The TLSSVM model and the SLSSVM model are obtained separately through training. The weight value of each model is also essential. Then, the weight values need to be determined. The TLSSVM model and the SLSSVM model are combined. The ULSSVM prediction model is obtained. If the weight values are obtained through experience, it will produce great subjectivity and uncertainty. Dempster-Shafer (D-S) has advantages in dealing with uncertainties caused by unknowns. It does not require prior probability and is easy to calculate. Therefore, it is widely used in data information fusion processing [8-10]. The traditional D-S theory has great limitations when dealing with conflicting information. The improved D-S theory can avoid this problem.
Parameter selection directly affects the prediction effect of LSSVM. In order to obtain the optimal parameters, the optimization method is generally used to optimize LSSVM parameters [11]. [12] utilized an adaptive cuckoo search method to optimize the kernel parameter and the penalty parameter of the LSSVM model. Compared with no parameter optimization, the mean absolute percentage error is reduced by nearly 30 %. Recently, there are many methods for LSSVM parameter optimization, such as particle swarm optimization (PSO), improved PSO, hybrid particle swarm optimization, and niche particle swarm optimization [13-16]. PSO method is suitable for LSSVM parameter optimization and is widely used. It is easy to implement, but it is slow for global convergence. Quantum particle swarm optimization (QPSO) is proposed based on PSO [17]. This model assumes that particles have quantum behavioral characteristics. The algorithm can search in the entire feasible area. So that the global search ability of QPSO is better than PSO.
In this research, an operating state prediction method for wind turbine bearings based on united LSSVM and QPSO is proposed. United LSSVM includes time LSSVM model and space LSSVM model. QPSO is used for parameter optimization of the models. The weights of time LSSVM and space LSSVM are determined by the improved D-S theory. The proposed method can improve the accuracy of the predicted values. The mean absolute error, the mean absolute percentage error, and the root mean squared error can be reduced. A case study shows that the prediction results based on this method can realize the prediction of the operating state of the wind turbine bearing.
2. Basic theory
2.1. Outline of LSSVM
LSSVM is an improved algorithm based on support vector machine (SVM). Equalization constraints and least squares loss function methods are introduced. The optimization problem becomes a linear equation. Quadratic programming problems are avoided. The complexity of the algorithm is reduced. The calculation speed of LSSVM is faster than SVM [18-20]. The detailed steps are as follows:
(1) Construct the linear equation: According to the basic principle of Structural Risk Minimization (SRM), the final training target can be expressed by the following:
where is the weight vector. is the regularization parameter that controls the degree of penalty for errors. is the kernel function. is the offset. is the variable representing the error.
(2) Construct Lagrange function: is introduced as a Lagrange multiplier, . Lagrange polynomial which is dual to Eq. (1) is constructed as:
(3) Determine the kernel function: The prediction model of generator bearing characteristic parameters has serious nonlinear characteristics. Therefore, the radial basis function (RBF) is selected as the kernel function. It can be expressed as:
where is the kernel width.
(4) Calculate the regression model: The offset and the support vector coefficient can be calculated. The regression model corresponding to the least squares support vector machine can be deduced as:
For more detailed information about LSSVM, readers can refer to [18-20].
2.2. Quantum particle swarm optimization
In order to improve the accuracy of the characteristic parameter prediction model and avoid the blindness of parameter selection, the quantum particle swarm optimization algorithm is used to optimize the kernel parameter and the penalty parameter of the LSSVM model. This process is a multi-parameter global optimization problem. QPSO is a probability optimization algorithm based on the principle of quantum computing. In quantum space, the properties of particles have changed in essence. This allows the algorithm to search in the entire feasible area. Therefore, the global search capability of QPSO is far superior to PSO. The detailed steps are as follows:
(1) Set the initial parameters: Including number of iterations, number of quantum particle groups, dimension and optimization range, etc. The particle position vector is randomly initialized according to the defined range.
(2) Calculate the fitness values: The fitness value of each particle is calculated by Eq. (5). The calculated fitness values of the particles are used as the local optimal fitness values , 1, 2, ..., . The minimum value in is selected as the global optimal fitness value :
where is the output value of the -th known sample. is the model prediction output value of the -th sample.
(3) Update the optimal fitness values: The position of each particle is updated by Eq. (6). The fitness value of each particle is recalculated. When the obtained local optimal fitness value is better than the previous generation, the corresponding is updated. When the obtained global optimal fitness value is better than the previous generation, is updated:
where is the current number of iterations. is of the -th particle. is the number of particle groups. is the particle position equation at . is a random number in the range of 0-1. The probability of ± taking + or - is 50 % respectively. is the contraction and expansion coefficient.
(4) Verify whether meet the end condition: If the number of iteration steps reaches the preset number of iterations, the optimization results of the kernel parameter and the penalty parameter are output. If not, go back to step (2) for further computations until meeting the termination conditions.
2.3. Improved dempster-Shafer
D-S theory is very effective for most data and information fusion, but when the evidence information is highly conflicting, it will produce results that are contrary to intuition. In response to this limitation, an improved D-S is proposed. The new method first assigns a weight to each evidence and uses the “discount rate” to adjust the basic credibility of all propositions in the identification framework. Then the traditional D-S is used for synthesis. This method preprocesses the evidence. It draws on the paradox elimination thought of adjusting reliability assignment.
The weight of the evidence is determined by the data information itself. The weight of the evidence is determined based on the distance between the evidence and the mean evidence. The original data is adjusted and fused. The conflict coefficient between multiple data information is effectively reduced. The detailed steps are as follows:
(1) Generate mean evidence: The generation of mean evidence can be realized by eliminating paradox thought in the literature [21]. The mean evidence is represented by . The -th element of can be obtained by Eq. (7):
where is the number of information sources. is the singleton of the identification framework .
(2) Calculate the distance between each evidence and the mean evidence: The distance between the -th evidence and the mean evidence is represented by . It can be calculated by Eq. (8):
(3) Calculate the minimum distance to the mean evidence: The evidence with the minimum distance from the mean evidence is selected (1 ).
(4) Calculate the weight of each evidence: The weights are assigned based on the distance between each evidence and the mean evidence. The smaller the distance, the higher the reliability and the greater the weight. The weight of the -th evidence is represented by . It can be obtained by Eq. (9):
(5) Recalculate the basic probability assignment: The “discount rate” of the basic probability of the evidence is represented by . It is used to adjust the basic probability by Eq. (10). The uncertainty subset is added to the identification framework, and its basic probability is calculated by Eq. (11):
(6) D-S synthesis: The traditional D-S is used for evidence synthesis.
3. Proposed parameter prediction scheme
If the time least squares support vector machine is used to predict the characteristic parameter, the historical test data of this parameter is used to predict the value of the parameter at a certain time in the future. The characteristic parameter set is expressed as . Specifically, part of the test data of the characteristic parameter before time is obtained. is the preset embedding dimension. Then the LSSVM is used to get the fitting function . The value of the characteristic parameter at time is predicted by . The interrelation is depicted by the term:
Traditional prediction models only consider the trend of the characteristic parameters over time. It cannot reflect the mutual influence and interrelationship among various characteristic parameters. In practical applications, the change of one parameter will affect the change of other parameters. In complex equipment systems, the correlation between different parameters cannot be ignored. In order to improve the prediction accuracy, the correlation between the parameters must be fully considered. Therefore, the traditional LSSVM modeling process needs to be improved. Incorporating the correlation between the parameters, a space LSSVM is proposed. Specifically, the test data of the characteristic parameter set at time is obtained. Then the space LSSVM is used to get the fitting function . The value of parameter at time is predicted by . The interrelation is depicted by the term:
TLSSVM prediction model considers the effect of time on the characteristic parameters. SLSSVM prediction model considers the interaction between various parameters. In order to improve the prediction accuracy, these two prediction models need to be fused reasonably. ULSSVM is built as a modified LSSVM.
When using time LSSVM, the predicted value of the characteristic parameter at time is expressed as . When using space LSSVM, the predicted value of the characteristic parameter at time is expressed as . Based on the above two predicted values of and , a combined function can be constructed:
The weighted form of the combined function is obtained by the following:
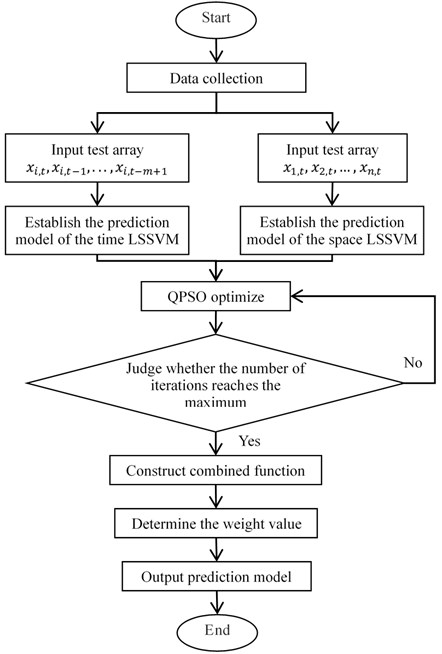
where is the weight of the TLSSVM prediction model. is the weight of the SLSSVM prediction model. Improved D-S theory is used to obtain the weight values. Select samples from test samples for evidence fusion analysis. Samples with close working condition data are preferred. A flowchart of the proposed parameter prediction scheme is shown in Fig. 1.
Take the prediction process of a certain characteristic parameter as an example. The concrete steps of the parameter prediction scheme based on ULSSVM, QPSO and improved D-S are as follows:
(1) The test data of the characteristic parameter in a period of time before is collected, and the collection results are represented by . TLSSVM is used to obtain the fitting map . is used to predict the value of at by Eq. (12). QPSO algorithm is used to optimize the kernel parameter and the penalty parameter of the LSSVM model. The prediction result is represented by .
(2) Collect the test data of all characteristic parameters at time . The collection results are . SLSSVM is used to obtain the fitting map . is used to predict the value of at by Eq. (13). QPSO algorithm is used to optimize the kernel parameter and the penalty parameter of the LSSVM model. The prediction result is represented by .
(3) The predicted value and the predicted value are used to construct a combined function in the form of Eq. (15).
(4) The weight values and in Eq. (15) are determined according to the actual measured value of the characteristic parameter at .
(5) According to the calculation results, the final prediction model is determined.
The final prediction model will be used to predict the value of at time .
Fig. 1Flowchart of the proposed parameter prediction scheme
4. Bearing parameter prediction based on ULSSVM
In order to verify the effectiveness of the proposed parameter prediction method, it is used for parameter prediction of bearing vibration signals and compared with actual measured values.
4.1. Data acquisition
Vibration signals of rotating machinery often contain rich operating status information [22-25]. Collect a set of bearing vibration signals under working conditions every 15 days. A total of 205 sets of vibration signal test data have been recorded. The sampling frequency is 20000 Hz, and the number of sampling points is 20480. 1-170 sets of vibration signal test data are used for training and learning. 171-205 sets of vibration signal test data are used for prediction and comparison.
The original data is difficult to reflect the operating state of the bearing. It is necessary to extract the characteristic parameters representing the operating state [26, 27]. There are many parameters that can be used to describe the operating state of the bearing [28, 29]. According to the existing research results of the bearing state prediction, 10 characteristic parameters are selected to represent the operating state of the bearing. The 10 parameters are mean value, rectified mean value, variance, root mean square (RMS), kurtosis, form factor, peak-to-average ratio (PAR), kurtosis factor, impulse factor and margin factor. These 10 parameters form a matrix . is the mean value. is the rectified mean value. is the variance. is RMS. is the kurtosis. is the form factor. is PAR. is the kurtosis factor. is the impulse factor. is the margin factor.
The mean value is the average value of all signal amplitudes. It can be expressed as:
where is the mean value. is the number of sampling points. is the amplitude of the -th sampling point.
The rectified mean value is the average of the absolute values of all amplitudes. It can be expressed as:
The variance is the average of the square of the difference between the amplitude of each signal and the average of all signal amplitudes. It represents the dynamic component of signal energy. It can be expressed as:
The RMS calculation process is to sum the squares of all signal amplitudes and take their average. Then take the square root of the calculation result. The root mean square is also called the effective value. It can be expressed as:
The kurtosis is used to describe the sharpness of the waveform. It can be expressed as:
The form factor is the ratio of the RMS to the rectified mean value. It can be expressed as:
PAR is the ratio of the peak value to the RMS. It represents the extreme degree of peaks in the waveform. It can be expressed as:
where is the peak value of the signal.
The kurtosis factor is used to describe the smoothness of the waveform. It is the distribution of variables. It can be expressed as:
The impulse factor is the ratio of the peak value to the rectified mean value. The difference between impulse factor and PAR is the denominator. For the same group of signals, the rectified mean value must be less than its effective value, so the impulse factor must be greater than the PAR. The impulse factor can be expressed as:
The margin factor is the ratio of the peak value to the square root amplitude. It is similar to PAR. The square root amplitude and the RMS are corresponding. It can be expressed as:
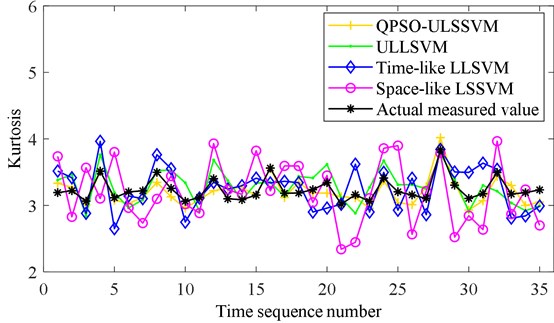
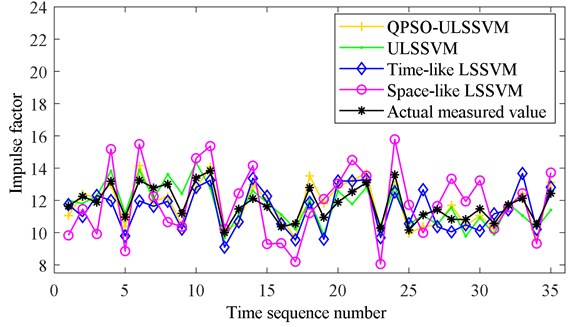
All state characteristic parameters of 205 sets of test data are calculated separately, including mean value, rectified mean value, variance, RMS, kurtosis, form factor, PAR, kurtosis factor, impulse factor, and margin factor. To reduce the complexity of the calculation, two characteristic parameters are selected as the prediction parameters, including the kurtosis and the impulse factor. The calculation results of the kurtosis are shown in Fig. 2(a). The calculation results of the impulse factor are shown in Fig. 2(b). It shows that the change regularities of the characteristic parameters are complicated.
Fig. 2Characteristic parameters of bearing vibration signal: a) the kurtosis and b) the impulse factor
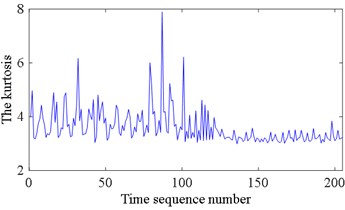
a)
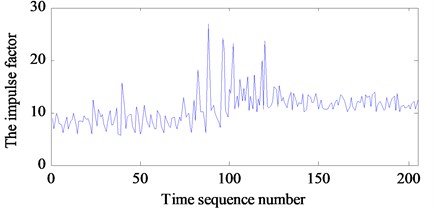
b)
4.2. Comparison of prediction methods
To evaluate the effectiveness and exhibit the superiority of QPSO ULSSVM algorithm in the prediction of characteristic parameters, the kurtosis and the impulse factor are predicted. TLSSVM, SLSSVM, ULSSVM and QPSO ULSSVM are used to predict the characteristic parameters separately. The mean absolute error , the mean absolute percentage error , and the root mean squared error are selected to evaluate these four methods. The expressions are as follows:
where is the number of samples. is the measured value. is the prediction value.
TLSSVM is used to predict the kurtosis. The kurtosis of 171-205 data sets are predicted based on 1-170 data sets. , , and are calculated based on TLSSVM predicted results and measured results.
SLSSVM is used to predict the kurtosis. The kurtosis of the 171-th data set is predicted based on all state characteristic parameters of the 170-th data set. of the 172-th data set is predicted based on all state characteristic parameters of the 171-th data set. of the -th data set is predicted based on all state characteristic parameters of the ()th data set. 171-205 data sets are predicted by using the same method. , , and are calculated based on SLSSVM predicted results and measured results.
ULSSVM is used to predict the kurtosis. The kurtosis of 171-205 data sets are predicted based on 171-205 prediction results of TLSSVM and SLSSVM, respectively. Weight values are determined by the improved D-S theory. ULSSVM predicted results are output based on weight values, TLSSVM prediction results, and SLSSVM prediction results. , , and are calculated based on ULSSVM predicted results and measured results.
QPSO ULSSVM is used to predict the kurtosis. TLSSVM and SLSSVM are optimized by QPSO. The kurtosis of 171-205 data sets are predicted based on optimized TLSSVM and SLSSVM, respectively. Then the weight values are calculated and the prediction results are output. , , and are calculated based on QPSO ULSSVM prediction results and measured results. The impulse factor is predicted by using the same method. The prediction results are shown in Fig. 3. It shows that the predicted values based on QPSO ULSSVM are closest to the actual measured values.
Table 1Evaluation values of the prediction results
Parameter | Method | Evaluation index | ||
Kurtosis | TLSSVM | 0.2331 | 0.0725 | 1.1245 |
SLSSVM | 0.3791 | 0.1175 | 1.8344 | |
ULSSVM | 0.1860 | 0.0576 | 0.8488 | |
QPSO ULSSVM | 0.1143 | 0.0351 | 0.5756 | |
Impulse factor | TLSSVM | 0.8372 | 0.0712 | 3.9071 |
SLSSVM | 1.3896 | 0.1183 | 6.5391 | |
ULSSVM | 0.5981 | 0.0505 | 2.8265 | |
QPSO ULSSVM | 0.5718 | 0.0487 | 2.6752 | |
The evaluation values of the prediction results are shown in Table 1, which can show that all of the four prediction methods can predict the characteristic parameters. This demonstrates that the bearing characteristic parameters have specific variation trend and could be predicted. Furthermore, the method based on QPSO ULSSVM yields the best accuracy, significantly higher than TLSSVM, SLSSVM, and ULSSVM. This will provide help for operating state recognition.
Fig. 3Predicted results of characteristic parameters: a) kurtosis and b) impulse factor
a)
b)
5. Case study
To verify the proposed method, bearing fault prediction is implemented. The vibration signal collection of the generator bearing is shown in Fig. 4. It is collected in the wind turbine nacelle. The acceleration sensor is installed on the bearing saddle. The vibration signal is collected periodically. Rolling bearings have four main states: normal, inner race fault, outer race fault, and ball fault. Collect 50 sets of vibration data for bearings of the same model in these four states, respectively. These data are called reference data. 10 characteristic parameters of each set of vibration data are calculated, respectively. The results of each state can be formed into a 50×10 matrix. This matrix is used as the reference matrix.
The vibration data of the same model bearing to be predicted is collected. Data is collected once a week. The total number of the collections is 20. The group number of each set of data is arranged from small to large according to time. These data are called test data. 10 characteristic parameters of each set of vibration data are calculated, respectively. The order of the 10 characteristic parameters is consistent with the reference matrix. Set the sequence number of the characteristic parameters: mean value is 1, rectified mean value is 2, variance is 3, RMS is 4, kurtosis is 5, form factor is 6, PAR is 7, kurtosis factor is 8, impulse factor is 9, margin factor is 10. Combine all calculation results into a matrix. The number of the row represents the time. The number of the column represents the sequence number of the characteristic parameter. It can be expressed as:
Fig. 4Data acquisition test device

QPSO ULSSVM is used to predict the characteristic parameters of the next moment. Take the mean value as an example. The mean values of 1-19 sets of test data are extracted as Eq. (30). The 10 characteristic parameters of 19-th set of test data are extracted as Eq. (31). LSSVM is used to fit the fitting function . is required to meet Eq. (32). LSSVM is used to fit the fitting function . is required to meet Eq. (33). The weight values of and are determined by using improved D-S theory. The weight values are and , respectively. The mean value at the next moment is predicted by Eq. (34). The other 9 parameters are rectified mean value, variance, RMS, kurtosis, form factor, PAR, kurtosis factor, impulse factor, and margin factor. The prediction method is the same as that of the mean value. The 10 characteristic parameters are predicted by using QPSO ULSSVM:
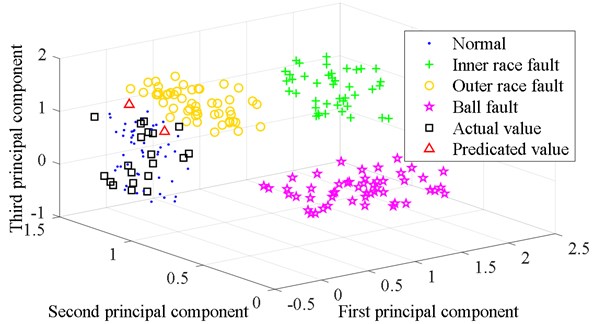
The parameter reference matrices of the four states are subjected to Laplacian eigenmaps (LE) dimensionality reduction processing. The feature vectors obtained by dimensionality reduction are fused. The feature vectors of the first three dimensions are extracted. The three-dimensional visualization of the reference matrix is obtained as shown in Fig. 5. The four states are well distinguished. The prediction results of 21-th set of data and the parameter reference matrices form a new matrix. This new matrix is reduced in dimension by LE. The feature vectors are fused and the first three dimensions of the feature vectors are extracted. The calculation result is expressed in the form of a three-dimensional image, as shown in Fig. 6. The prediction data and the normal state data are distributed in the same area of the space. The prediction result is that the bearing state is normal at the next moment. The bearing is working normally after a week.
Fig. 5Three-dimensional classification diagram of the four states
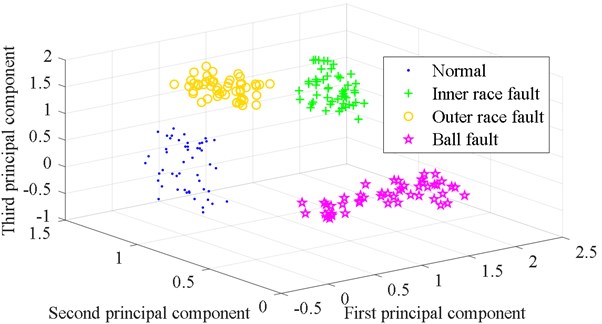
Fig. 6Three-dimensional classification diagram of the prediction result based on QPSO ULSSVM
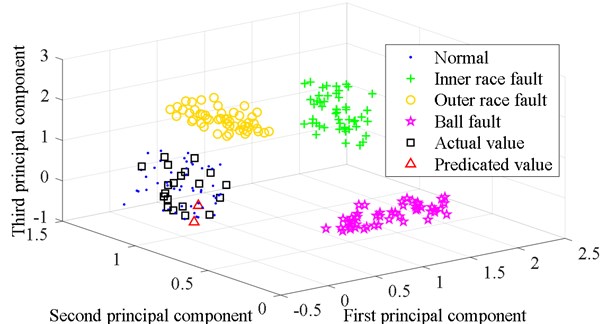
Fig. 7Three-dimensional classification diagram of the prediction result based on LSSVM
As a comparison, the characteristic parameters prediction method uses TLSSVM. The 10 characteristic parameters of 21-th set of data are predicted by using traditional TLSSVM. The prediction results and the parameter reference matrices form a new matrix. This new matrix is also reduced in dimension by LE. The first three feature vectors are extracted. The calculation result is expressed in the form of a three-dimensional image, as shown in Fig. 7. The prediction data, the outer race fault data, and the normal state data are partially overlapped. The result is not certain. This shows that the accuracy of state parameter prediction is related to generator bearing’s operating state prediction. QPSO ULSSVM improves the accuracy of characteristic parameters prediction. The realization of the generator bearing’s operating state prediction is based on QPSO ULSSVM.
6. Conclusions
In this paper, ULSSVM and QPSO is used to predict the operating status of the wind turbine bearing. The observations and conclusions of the study are summarized as follows:
1) ULSSVM, a novel parameter prediction method, is proposed to effectively predict the operating state parameters. The results show that the new method is better than the TLSSVM and SLSSVM methods.
2) ULSSVM combines the time LSSVM and the space LSSVM. Improved D-S method is used to determine the weight of each model. It helps ULSSVM achieve better results in the parameter prediction of wind turbine bearing.
3) The novel strategy of utilizing combined ULSSVM and QPSO to parameter prediction in wind turbine bearing is developed, and the algorithm is proved reliable to predict the working state of wind turbine bearing. It was provided an effectual way for the operating state prediction of wind turbine bearing to combine ULSSVM and QPSO.
References
-
N. Tazi, E. Châtelet, and Y. Bouzidi, “Using a hybrid cost-FMEA analysis for wind turbine reliability analysis,” Energies, Vol. 10, No. 3, p. 276, Feb. 2017, https://doi.org/10.3390/en10030276
-
R. Nishat Toma and J.-M. Kim, “Bearing fault classification of induction motors using discrete wavelet transform and ensemble machine learning algorithms,” Applied Sciences, Vol. 10, No. 15, p. 5251, Jul. 2020, https://doi.org/10.3390/app10155251
-
L. Jiang and S. Guo, “Modified kernel marginal fisher analysis for feature extraction and its application to bearing fault diagnosis,” Shock and Vibration, Vol. 2016, pp. 1–16, 2016, https://doi.org/10.1155/2016/1205868
-
H. André, F. Allemand, I. Khelf, A. Bourdon, and D. Rémond, “Improving the monitoring indicators of a variable speed wind turbine using support vector regression,” Applied Acoustics, Vol. 166, p. 107350, Sep. 2020, https://doi.org/10.1016/j.apacoust.2020.107350
-
G. X. D. Wang A., “A grey model-least squares support vector machine method for time series prediction,” Tehnicki vjesnik – Technical Gazette, Vol. 27, No. 4, pp. 1126–1133, Aug. 2020, https://doi.org/10.17559/tv-20200430034527
-
S. Younas, Y. Mao, C. Liu, W. Liu, T. Jin, and L. Zheng, “Efficacy study on the non-destructive determination of water fractions in infrared-dried Lentinus edodes using multispectral imaging,” Journal of Food Engineering, Vol. 289, p. 110226, Jan. 2021, https://doi.org/10.1016/j.jfoodeng.2020.110226
-
Z. Tian, “Short-term wind speed prediction based on LMD and improved FA optimized combined kernel function LSSVM,” Engineering Applications of Artificial Intelligence, Vol. 91, p. 103573, May 2020, https://doi.org/10.1016/j.engappai.2020.103573
-
T. Denœux and P. P. Shenoy, “An interval-valued utility theory for decision making with Dempster-Shafer belief functions,” International Journal of Approximate Reasoning, Vol. 124, pp. 194–216, Sep. 2020, https://doi.org/10.1016/j.ijar.2020.06.008
-
E. Koksalmis and Kabak, “Sensor fusion based on Dempster-Shafer theory of evidence using a large scale group decision making approach,” International Journal of Intelligent Systems, Vol. 35, No. 7, pp. 1126–1162, Jul. 2020, https://doi.org/10.1002/int.22237
-
J. Dunham, E. Johnson, E. Feron, and B. German, “Automatic updates of transition potential matrices in dempster-shafer networks based on evidence inputs,” Sensors, Vol. 20, No. 13, p. 3727, Jul. 2020, https://doi.org/10.3390/s20133727
-
Q. Xiong, Y. Xu, Y. Peng, W. Zhang, Y. Li, and L. Tang, “Low-speed rolling bearing fault diagnosis based on EMD denoising and parameter estimate with alpha stable distribution,” Journal of Mechanical Science and Technology, Vol. 31, No. 4, pp. 1587–1601, Apr. 2017, https://doi.org/10.1007/s12206-017-0306-y
-
G. M. Jiang, Z. J. Chen, X. Z. Li, and X. Q. Yan, “Short-term prediction of wind power based on EEMD-ACS-LSSVM,” (in Chinese), Acta Energiae Solaris Sinica, Vol. 41, No. 5, pp. 77–84, 2020.
-
X. Song, J. Zhao, J. Song, F. Dong, L. Xu, and J. Zhao, “Local demagnetization fault recognition of permanent magnet synchronous linear motor based on S-transform and PSO-LSSVM,” IEEE Transactions on Power Electronics, Vol. 35, No. 8, pp. 7816–7825, Aug. 2020, https://doi.org/10.1109/tpel.2020.2967053
-
H. Zhu and T. Liu, “Rotor displacement self-sensing modeling of six-pole radial hybrid magnetic bearing using improved particle swarm optimization support vector machine,” IEEE Transactions on Power Electronics, Vol. 35, No. 11, pp. 12296–12306, Nov. 2020, https://doi.org/10.1109/tpel.2020.2982746
-
S. Sun, J. Fu, A. Li, and P. Zhang, “A new compound wind speed forecasting structure combining multi-kernel LSSVM with two-stage decomposition technique,” Soft Computing, Vol. 25, No. 2, pp. 1479–1500, Jan. 2021, https://doi.org/10.1007/s00500-020-05233-8
-
Y. Li and F. Xu, “Structural condition monitoring and identification of laser cladding metallic panels based on an acoustic emission signal feature optimization algorithm,” Structural Health Monitoring, Vol. 20, No. 3, pp. 1052–1073, May 2021, https://doi.org/10.1177/1475921720945637
-
X. Gu and C. Chen, “Rolling bearing fault signal extraction based on stochastic resonance-based denoising and VMD,” International Journal of Rotating Machinery, Vol. 2017, pp. 1–12, 2017, https://doi.org/10.1155/2017/3595871
-
Z. J. Tang, F. Ren, T. Peng, and W. B. Wang, “A least square support vector machine prediction algorithm for chaotic time series based on the iterative error correction,” (in Chinese), Acta Physica Sinica, Vol. 63, No. 5, p. 050505, 2014.
-
Z. J. Tang, T. Peng, and W. B. Wang, “A local least square support vector machine prediction algorithm of small scale network traffic based on correlation analysis,” (in Chinese), Acta Physica Sinica, Vol. 63, No. 13, p. 130504, 2014.
-
N. Sapankevych and R. Sankar, “Time series prediction using support vector machines,” IEEE Computational Intelligence Magazine, Vol. 4, No. 2, pp. 24–38, May 2009, https://doi.org/10.1109/mci.2009.932254
-
C. K. Murphy, “Combining belief functions when evidence conflicts,” Decision Support Systems, Vol. 29, No. 1, pp. 1–9, Jul. 2000, https://doi.org/10.1016/s0167-9236(99)00084-6
-
D. P. Jena and S. N. Panigrahi, “Automatic gear and bearing fault localization using vibration and acoustic signals,” Applied Acoustics, Vol. 98, pp. 20–33, Nov. 2015, https://doi.org/10.1016/j.apacoust.2015.04.016
-
D. Abboud, Y. Marnissi, and M. Elbadaoui, “Optimal filtering of angle-time cyclostationary signals: Application to vibrations recorded under nonstationary regimes,” Mechanical Systems and Signal Processing, Vol. 145, p. 106919, Nov. 2020, https://doi.org/10.1016/j.ymssp.2020.106919
-
X. Wen, G. Lu, J. Liu, and P. Yan, “Graph modeling of singular values for early fault detection and diagnosis of rolling element bearings,” Mechanical Systems and Signal Processing, Vol. 145, p. 106956, Nov. 2020, https://doi.org/10.1016/j.ymssp.2020.106956
-
K. J. M. Rai A., “A novel health indicator based on the Lyapunov exponent, a probabilistic self – organizing map, and the Gini-Simpson index for calculating the RUL of bearings,” Measurement, Vol. 164, p. 108002, 2020.
-
Y. Liu, Q. Qian, F. Liu, S. Lu, Q. He, and J. Zhao, “Wayside bearing fault diagnosis based on envelope analysis paved with time-domain interpolation resampling and weighted-correlation-coefficient-guided stochastic resonance,” Shock and Vibration, Vol. 2017, pp. 1–17, 2017, https://doi.org/10.1155/2017/3189135
-
X. Zhu, X. Luo, J. Zhao, D. Hou, Z. Han, and Y. Wang, “Research on deep feature learning and condition recognition method for bearing vibration,” Applied Acoustics, Vol. 168, p. 107435, Nov. 2020, https://doi.org/10.1016/j.apacoust.2020.107435
-
P. Ma, “Fault diagnosis of rolling bearings based on local and global preserving embedding algorithm,” Journal of Mechanical Engineering, Vol. 53, No. 2, p. 20, 2017, https://doi.org/10.3901/jme.2017.02.020
-
H. S. Zhao, L. Li, and Y. Wang, “Fault feature extraction method of wind turbine bearing based on blind source separation and manifold learning,” (in Chinese), Acta Energiae Solaris Sinica, Vol. 37, No. 2, pp. 269–275, 2016.
About this article

This research was financially supported by the National Natural Science Foundation of China (No. 51675350), Scientific Research Fund Project of Liaoning Provincial Department of Education (No. LG202031) and the Doctoral Research Startup Fund (No. 1010147000818 and No. 1010147000819).
